
ruHumanEval
Task Description
Russian HumanEval (ruHumanEval) is the Russian analogue of the original HumanEval dataset, created to evaluate the ability of language models to generate code in the Python programming language to solve simple problems. The dataset is aimed at measuring the functional correctness of code generation based on information from the function's documentation lines — a text description of the function's operation and several examples of results for different input data.
Warning: This is a diagnostic dataset with an open test and is not used for general model evaluation on the benchmark. Results on the HumanEval and the ruHumanEval datasets cannot be directly compared with each other. Open data is the public test set of the original ruHumanEval dataset. Do not use it in train purposes!
Keywords: PLP, programming, Python
Motivation
This task tests the ability of models to generate simple Python programs based on a description (condition) in natural language. Since large models have in their training corpus a proportion of texts (programs) written in various programming languages, they are assumed to have the ability to understand and write code for simple tasks.
Dataset Description
Data Fields
instructionis a string containing instructions for the task;inputsis a dictionary that contains the following information:functionis a line containing the function signature, as well as its docstring in the form of an unwritten function;testsis a list of dictionaries that contain input data of test cases for a given task (variants of input data on which the final function code is tested);
outputsis a two-dimensional array of size (n_samples, n_tests), where n_samples is the number of samples required to calculate the pass@k metric, n_tests is the number of test cases in tests; each list in the outputs is the same and contains correct answers to all test cases;metais a dictionary containing meta information:idis an integer indicating the index of the example;canonical_solutionis the canonical solution;entry_pointis the function name.
Prompts
For this task 10 prompts of varying difficulty were created. Example: "Дан шаблон функции(ий) с описанием работы этой функции в качестве условия задачи. Допишите программу\n{function}"
Dataset Creation
The open set was translated into Russian from the dataset openai_humaneval. We corrected typos in the docstring and canonical solutions and made the corrections described in [2].
The test set was manually collected from open sources according to the format of the original open set and also adjusted to avoid data leakage in training.
Evaluation
Metrics
The model is evaluated using the pass@k metric, which is computed as follows:
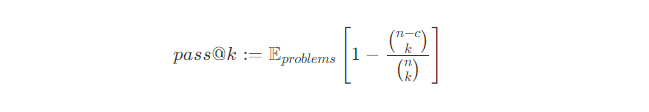
Notation: n is the total number of generated solution options, c is the number of solutions that are correct, k is the selected indicator, how many options are taken into account.
To calculate pass@k, n ≥ k solutions are generated for each problem and are run through test cases (we use n = 200 and k ≤ 100 and an average of 10 test cases per problem). Then, the number of the correct solutions is calculated (c ≤ n). The solution is considered to be correct if it passes all test cases. That means the result of running solutions on test cases should be equal to the correct answers (outputs) for one problem. Such an evaluation process yields an unbiased score.
Human evaluation
Dataset includes algorithmic problems that require knowledge of the Python programming language, which is too complex skill for an average annotator. All problems have strict solutions, therefore all human evaluation metrics are taken as 1.0.
References
[1] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[2] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, Lingming Zhang Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation.