
Описание задачи
Russian HumanEval (ruHumanEval) является русским аналогом оригинального датасета HumanEval [1], созданного для оценки возможностей языковых моделей генерировать код на языке программирования Python для решения простых задач. Датасет направлен на измерение функциональной корректности генерации кода на основе информации из строк документации функции — текстового описания работы функции и нескольких примеров результатов для разных входных данных.
Важно! В целях избежания утечки данных, для HumanEval мы создали НОВУЮ закрытую тестовую часть датасета, которая по своей структуре и методологии полностью повторяет оригинальный тест, но содержит новые примеры. В связи с этим результаты моделей на HumanEval и ruHumanEval нельзя напрямую сравнивать между собой.
Замечание: Это диагностическое задание с открытым тестом. Результат на ней не участвует в расчет общего результата (Total score) модели на бенчмарке. Результаты моделей на HumanEval и ruHumanEval нельзя напрямую сравнивать между собой. Помимо это, так как открытые данные это публичный тест из оригинального HumanEval, не используйте их для обучения!
Ключевые слова: PLP, программирование, Python.
Мотивация
Данная задача проверяет способность моделей генерировать простые программы на языке Python по описанию (условию) на естественном языке. Так как большие модели имеют в обучающем корпусе долю текстов (программ) написанных на различных языках программирования, предполагается, что они обладают способностью понимать и составлять код для простых задач.
Поля Данных
instruction— строка, содержащая формулировку запроса к языковой модели;inputs— словарь, содержащий входные данные задания:function— строка, содержащая сигнатуру функции, а также ее док-строку в виде недописанной функции;tests— строка со списком словарей, которая содержит входные данные тестовых кейсов для данной задачи (вариантов входных данных, на которых тестируется итоговый код функции);
outputs— двумерный массив строк размера (n_samples, n_tests), где n_samples - количество сэмплов, требуемое для подсчета метрики pass@k, n_tests - количество тестовых кейсов в tests; каждый список в outputs одинаков и содержит корректные ответы в виде строк на все тестовые кейсы.meta— cловарь, содержащий метаинформацию:id— номер примера;canonical_solution— каноническое решение задачи [только в демонстрационных примерах];entry_point— имя функции.
Промпты
Для датасета было подготовлено 10 промптов разной сложности.
Пример промпта: "Дан шаблон функции(ий) с описанием работы этой функции в качестве условия задачи. Допишите программу\n{function}"
Создание датасета
Открытый сет — это публичный открытый тестовый датасет openai_humaneval с переведенными на русский язык описаниями условий. В сете исправлены некоторые опечатки в условиях и решениях, а также учтены исправления, описанные в [2].
Тестовый закртый сет был собран из открытых источников вручную по формату оригинального открытого сета и также скорректирован во избежание утечки данных в обучении.
Оценка
Метрики
Оценка решения проводится с помощью метрики pass@k, вычисляемой по формуле:
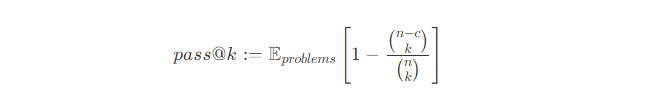
Обозначения: n - общее количество сгенерированных вариантов решений, c - число решений, которые являются корректными, k - выбираемый показатель, сколько вариантов учитываем.
Чтобы оценить pass@k, генерируется n ≥ k вариантов решения для каждой задачи, через которые прогоняются тестовые кейсы (используем n = 10 и k ≤ 10 и в среднем 10 тест-кейсов на задачу), считается количество правильных решений при условии, что всегда c ≤ n. Правильность решения определяется по результатам прохождения модульных тестов, то есть результат прогонов решений на тест-кейсах должен совпасть с правильными ответами на тест-кейсы одной задачи. Полученная в результате оценка является несмещеной.
Человеческая оценка
Датасет включает в себя алгоритмические задачи, для решения которых требуется знание языка программирования Python, что является слишком сложной задачей для среднего разметчика. Все задачи имеют строгие решения, потому все метрики человеческой оценки принимаются за 1.0.
Ссылки
[1] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[2] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, Lingming Zhang Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation