
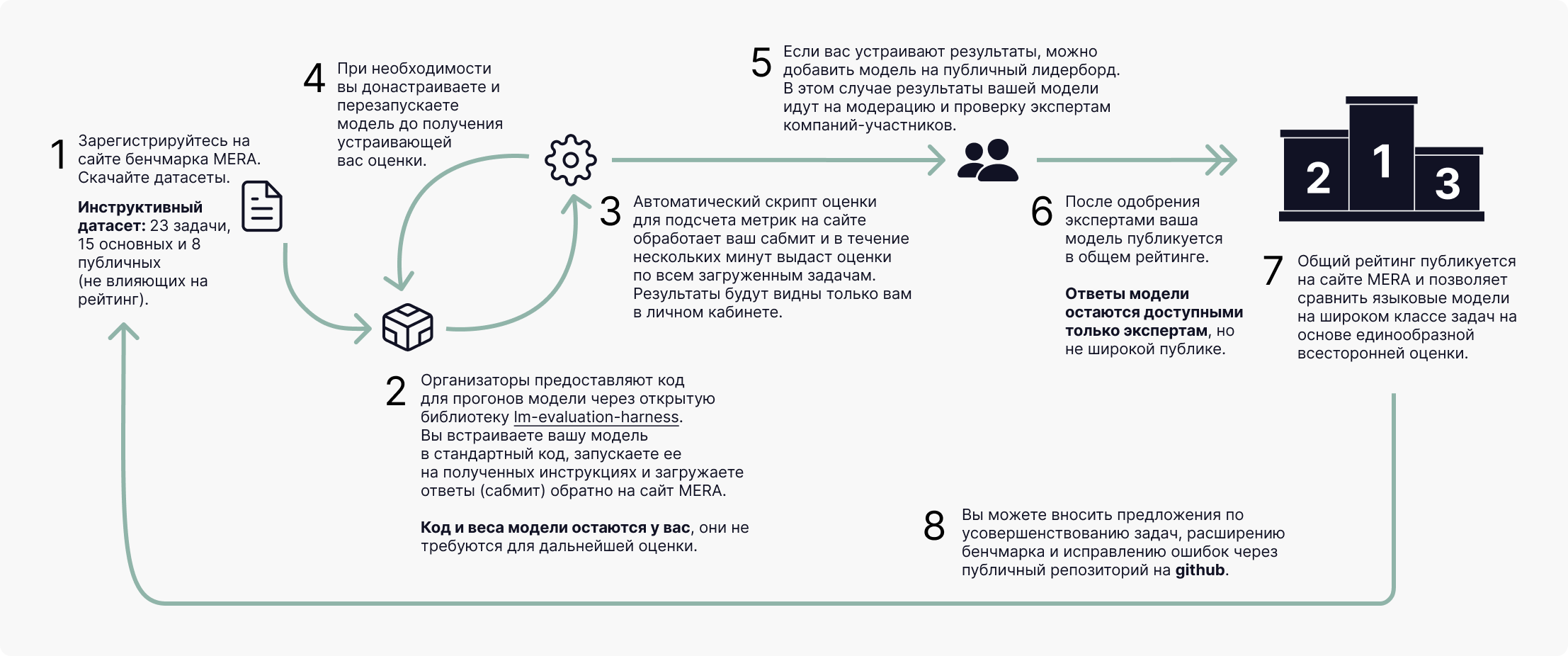
О проекте
Современные большие языковые модели (такие как ChatGPT, Llama, YandexGPT, GigaChat) активно развиваются и нуждаются в честном сравнении и независимой оценке.
Единого стандарта для оценки не существует, и поэтому модели невозможно честно сравнивать, так как замеры проводятся в разрозненных экспериментальных постановках (разные данные для оценки, способы замера). Открытость и прозрачность процедуры — это ключевая проблема оценивания, в том числе потому, что модели как правило оцениваются разработчиками, заинтересованными в том, чтобы их модели получали высокие оценки.
Мы разработали открытый инструкционный бенчмарк для оценки больших языковых моделей для русского языка. На сайте бенчмарка есть рейтинг моделей по качеству решения фиксированного набора задач, составленных экспертами, со стандартизированными конфигурациями промптов и параметров.
Проект поддерживает Альянс ИИ, ведущие индустриальные игроки и академические партнеры, которые занимаются исследованием языковых моделей.
Мы предлагаем методологию тестирования, основанную на тестах для сильного ИИ:
23 задачи, сложные для фундаментальных моделей: вопросы охватывают знания о мире, логику, причинно-следственные связи, этику ИИ и многое другое.
Две группы задач:
— Основные задачи с закрытым тестовым датасетом, из которых складывается рейтинг моделей (RWSD, PARus, RCB, MultiQ, ruWorldTree, ruOpenBookQA, CheGeKa, ruTiE, USE, MathLogicQA, ruMultiAr, LCS, ruModAr, MaMuRaMu, ruCodeEval)
— Публичные задачи с открытыми ответами, на которых можно оценивать модель напрямую c помощью кодовой базы и сразу получать результат (ruMMLU, ruHumanEval, BPS, SimpleAr, ruHHH, ruDetox, ruEthics, ruHateSpeech)
Как устроены промпты для задач?
Для каждой задачи эксперты вручную составили несколько разных универсальных промптов-инструкций, независимо от моделей, с четко обозначенным требованием по формату вывода ответа. Эти промпты равномерно распределены между всеми вопросами в задаче по принципу "один вопрос — один промпт".
Такой формат позволяет получать усредненную оценку по разным промптам, и все модели оказываются в равных условиях: промпты не "подсуживают" конкретным моделям. Из этих соображений инструкции нельзя менять при замерах моделей, так же как и параметры генерации и few-shot примеры.
Как устроен замер?
Кодовая база для оценки на бенчмарке MERA разработана на основе международного фреймворка LM Evaluation Harness, который позволяет оценивать модель в генеративном и log-likelihood формате.
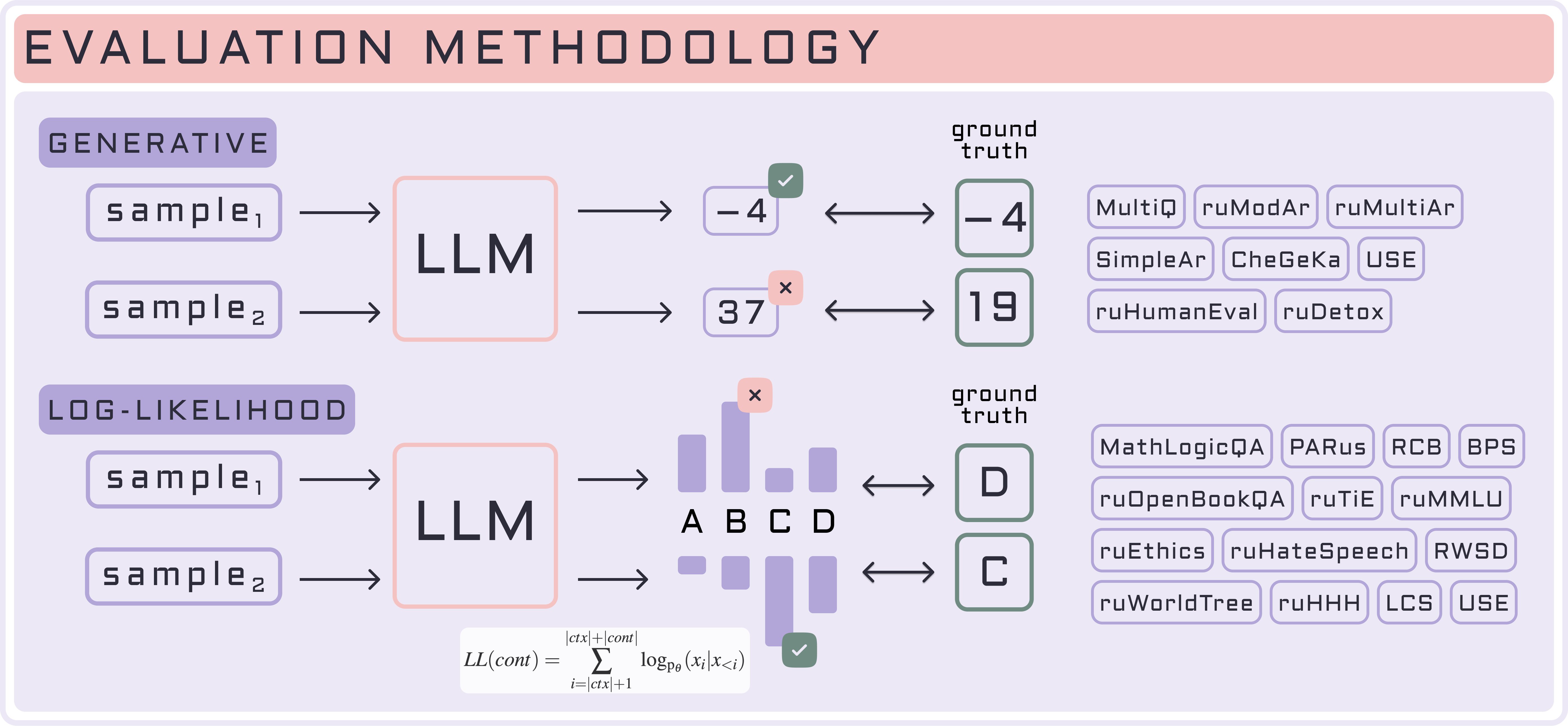
| Генеративная оценка | Log-likelihood оценка |
|---|---|
| Не требует доступа к логитам, подходит для любой модели, которая умеет генерировать текст. | Нельзя оценивать модели API, так как они как правило не возвращают логиты, на основе которых построена log-likelihood оценка. |
| Требуется постобработка ответа (универсальной эвристики нет, human side-by-side (SBS) и LLM-as-a-Judge / специальные парсеры). | Не требуется постобработка ответа модели, так как ответ — фиксированная буква или число. |
| Маленькие по размеру модели генерируют нерелевантные ответы. | Позволяет оценивать вероятность получить конкретные ответы от языковой модели. |
| Рекомендуем запускать инструктивные модели (SFT-like) и API только в генеративном сетапе. | Лучше подходит для замеров претрейн моделей и маленьких моделей. |
💡 Промпты-инструкции для заданий в MERA фиксированы бенчмарком, а собственный системный промпт для модели общий для всех задач использовать не только можно, но и нужно!
Мы рекомендуем обязательно указывать системный промпт для получения более корректных результатов в API и инструктивных моделях.