
About the project
Modern large language models (like ChatGPT, Llama, YandexGPT, and GigaChat) are developing rapidly and require objective comparison and independent evaluation.
We observe from international experience that model evaluation is conducted on different benchmarks and in various experimental setups and scenarios, leading to a lack of understanding of what models can genuinely accomplish and making it impossible to compare the models' abilities. Openness and transparency in the evaluation process are the key issues because any model will be assessed by the developer according to their methodology claiming the superiority of their models.
We have developed an open instructional benchmark for evaluating large language models for the Russian language. The benchmark website provides a ranking of models based on their performance in solving a fixed set of tasks compiled by experts with standardized configurations of prompts and parameters.
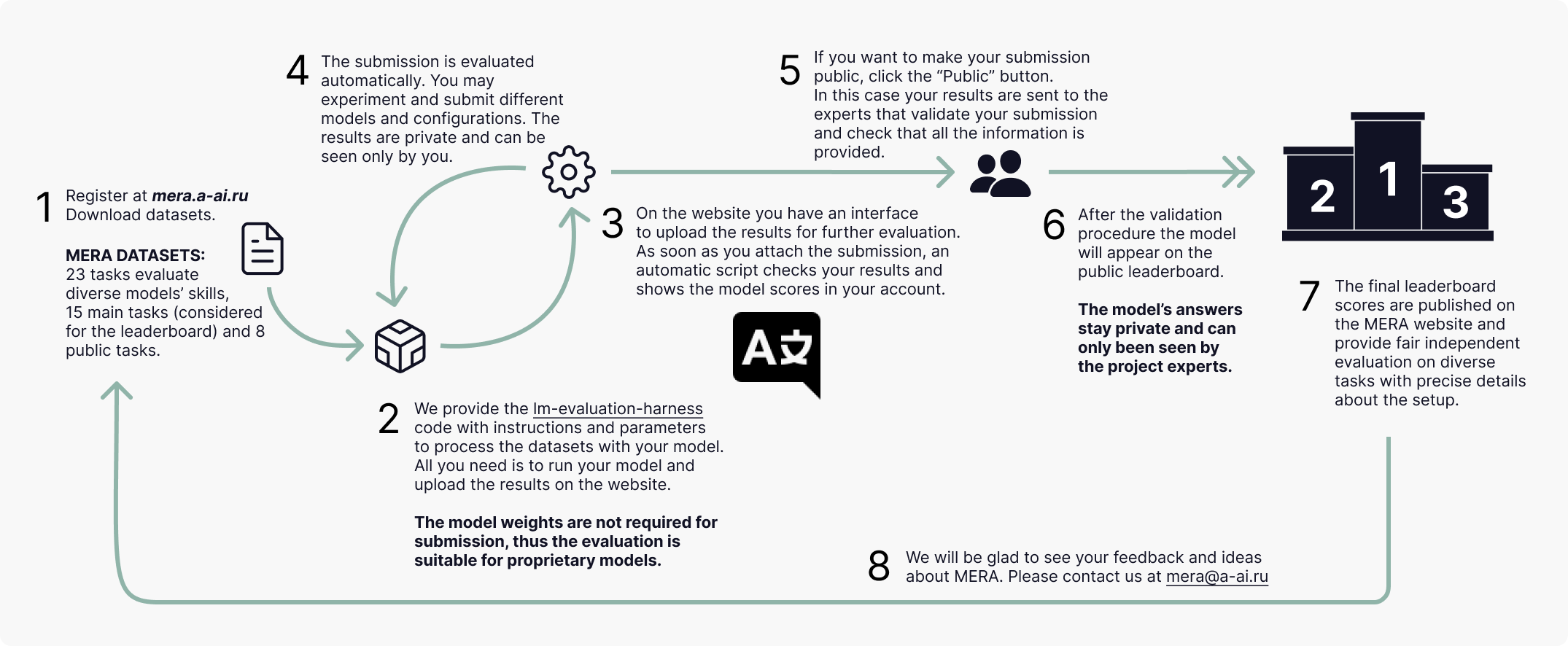
We propose a new methodology to evaluate SOTA language models
23 challenging tasks for large language models: the questions cover world knowledge, logic, cause-and-effect relationships, AI ethics, and much more.
There are two groups of tasks:
— Main tasks with a closed test dataset that make up the model ranking (RWSD, PARus, RCB, MultiQ, ruWorldTree, ruOpenBookQA, CheGeKa, ruTiE, USE, MathLogicQA, ruMultiAr, LCS, ruModAr, MaMuRaMu, ruCodeEval)
— Public tasks with open answers where you can directly evaluate the model using the codebase and immediately get results (ruMMLU, ruHumanEval, BPS, SimpleAr, ruHHH, ruDetox, ruEthics, ruHateSpeech)
How are task prompts designed?
For each task, experts have manually created several diverse universal model-agnostic instruction prompts with clearly defined requirements for the answer output format. These prompts are uniformly distributed among all questions in the task so that each question is assigned exactly one prompt.
This format allows to obtaining an average score based on different prompts and all models are evaluated in equal conditions: prompts do not "favor" specific models. For these reasons, instructions as well as generation parameters and few-shot examples cannot be changed within model evaluation.
How is measurement done?
The benchmark's scoring system is based on the international LM Evaluation Harness framework, which provides generative and log-likelihood setup for model evaluation.
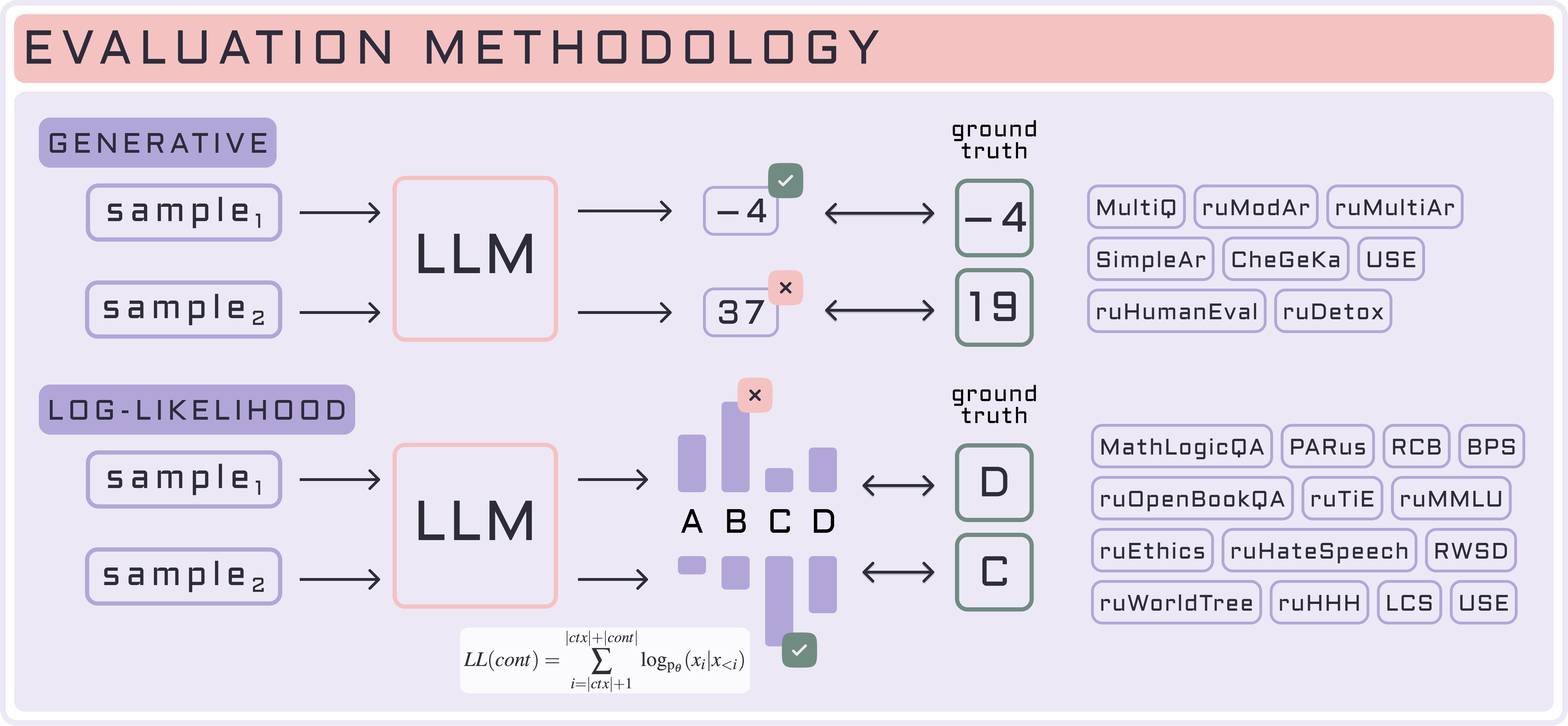
| Generative evaluation | Log-likelihood evaluation |
|---|---|
| Does not require access to logits, suitable for any model capable of generating text. | Is not suitable for API models since they typically do not return logits used in log-likelihood evaluation. |
| Requires answer post-processing (no universal heuristics, human SBS and LLM-as-a-Judge / special parsers). | Does not require model response post-processing because the answer is a fixed letter or number. |
| Smaller models tend to generate irrelevant responses. | Allows to measure the probability of specific responses from a language model. |
| We recommend to evaluate instructive models (SFT-like) and APIs only in generative setup. | Better suited for evaluation of pretrained models and smaller models. |
💡 Instruction prompts for tasks in MERA are fixed in the benchmark, yet it is recommended to model-specific system prompt for the model (the same for all tasks).
We recommend specifying the system prompt to obtain more accurate results from both API and instructive models.