
Task description
LabTabVQA is a Russian-language dataset for answering questions based on images of tables from the field of medicine. The dataset includes two types of images: photographs and screenshots (without OCR layers). Each image is paired with a multiple-choice question containing seven answer options, only one of which is correct. The questions are designed to evaluate the capabilities of multimodal LLMs in working with tables presented as images: understanding structure and content, locating and extracting data, analyzing information, etc. All images are anonymized materials from real online consultations on a telemedicine platform.
Data description
Data fields
Each dataset question includes data in the following fields:
instruction[str] — Each dataset question includes data in the following fields:inputs— Input data that forms the task for the model.question[str] — Text of the question.image[str] — Path to the image file related to the question.option_a[str] — Answer option A.option_b[str] — Answer option B.option_c[str] — Answer option C.option_d[str] — Answer option D.option_e[str] — Answer option E.option_f[str] — Answer option F.option_g[str] — Answer option G.
outputs[str] — The correct answer to the question.meta— Metadata related to the test example, not used in the question (hidden from the tested model).id[int] — Identification number of the question in the dataset.categories— Categorial features characterizing the test example.question_type[str] — Question category.question_text[str] — Task type by question text.question_source[str] — Question source: human if the question is written by a human, or generated if the question is generated with the o4-mini model.
image— Image metadata.synt_source[list] — Sources used to generate or recreate data for the question, including names of generative models.source[list] — Information about the origin of the image — according to the image classification for MERA datasets.type[list] — Image type — according to the image classification for MERA datasets.content[list] — Image content — according to the image classification for MERA datasets.context[list] — Accompanying context present in the image — according to the image classification for MERA datasets.
rows[int] — The number of rows in the table on the image.columns[int] — The number of columns in the table on the image.
Evaluation
Metrics
Metrics for aggregated evaluation of responses:
- `Exact match`: Exact match is the average of scores for all processed cases, where a given case score is 1 if the predicted string is the exact same as its reference string, and is 0 otherwise.
Human baseline
Human baseline is an evaluation of the average human answers to the benchmark questions. The evaluation is carried out using the same metrics as for the models.
The human baseline was established via independent annotation on the TagMe platform, with 5-way overlap. Assessors were asked to answer the generated questions, and the instructions included annotated examples (the same used for few-shot prompting). The final prediction was determined by majority vote among assessors' responses (at least 3 out of 5 must match), and the metric amounted to 93.9%. In 11 samples (3.35% of all data), a majority vote could not be reached, so they were excluded from evaluation.
Evaluation results:
- Exact match – 0.91
Motivation
LabTabVQA was created to evaluate the ability of multimodal models to work with tabular information presented in image form in Russian language. Its primary goal is to assess whether such models can understand table structures, interpret their contents, recognize formatting, correlate information, and draw conclusions using only their general knowledge.
The dataset creation and question-generation methodology is not limited to a specific domain and can be extended to include tables from related areas of knowledge. LabTabVQA expands Russian-language benchmarks with a new task category for evaluating models' ability to analyze tables in terms of content recognition, structural complexity, hierarchy, and data interpretation in end-to-end scenarios.
Dataset creation
The dataset was built using 697 real images from a telemedicine consultation platform.
Using the GPT-4o Mini model, we annotated images according to two binary criteria:
- presence of a table in the image;
- photo or screenshot.
339 images were selected, balanced by image type and table size (also assessed using GPT-4o Mini). For 138 samples, questions were written by experts; for the remaining 201, questions were generated using an AI-agent system composed of the following components:
1. QuestionGenerator (GPT-o4 Mini): generates a candidate question with 7 answer options based on the image and question category;
2. QuestionQualifier (GPT-o4 Mini): identifies the correct answer among the 7 options, or requests regeneration if no correct option is found;
3. Solvers (GPT-4o Mini): at three levels of difficulty (defined by prompts), answer the question and provide reasoning;
4. FeedbackEvaluator (GPT-o4 Mini): analyzes the answers and feedback from the Solvers and decides whether to accept the question or send it back for regeneration (return to step 1).
The generated examples were validated on the TagMe platform (with 3-way overlap) based on the following criteria:
- the question is based on the table shown in the image;
- the question does not require domain-specific knowledge (all required information is in the image/table);
- the question cannot be answered without using the table/image.
Similarly, the correct answer was selected by assessors. A correct answer was defined as:
- the answer proposed by the question generation system, if at least 2 out of 3 assessors agreed with it;
- the answer chosen by at least 2 out of 3 assessors, even if it differed from the generated answer, provided it was additionally validated by a meta-assessor.
Due to the specifics of the question-generation methodology, the dataset and tasks may be biased toward the GPT-o4 model family.
Contributors
Amina Miftakhova, Ivan Sviridov
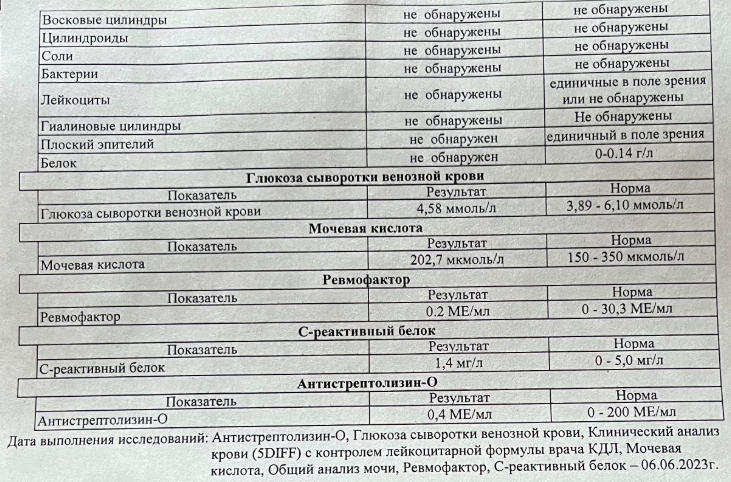 "question": "Для скольких показателей нормальные значения указаны в виде числового диапазона?"
},
"outputs": "B",
"meta": {
"id": 346,
"categories": {
"question_type": "Формат и оформление данных - Формат значений",
"question_text": "Подсчёт количества",
"question_source": "human"
},
"image": {
"synt_source": [],
"source": [
"photo"
],
"type": [
"systematic"
],
"content": [
"info"
],
"context": [
"no_context"
]
},
"rows": 11,
"columns": 3
}
}
```
"question": "Для скольких показателей нормальные значения указаны в виде числового диапазона?"
},
"outputs": "B",
"meta": {
"id": 346,
"categories": {
"question_type": "Формат и оформление данных - Формат значений",
"question_text": "Подсчёт количества",
"question_source": "human"
},
"image": {
"synt_source": [],
"source": [
"photo"
],
"type": [
"systematic"
],
"content": [
"info"
],
"context": [
"no_context"
]
},
"rows": 11,
"columns": 3
}
}
```
 GitHub
GitHub