
Описание задачи
LabTabVQA — вопросно-ответный датасет на русском языке по изображениям с табличными данными из медицинского домена. В данных представлены изображения двух типов: фотографии и скриншоты (без OCR-слоя). К каждому изображению прилагается вопрос с семью вариантами ответа, где только один правильный. Вопросы позволяют оценить способности мультимодальных LLM по работе с таблицами, представленными в виде изображений: понимать структуру и содержимое, находить и извлекать данные, анализировать информацию и т. п. Все изображения — это анонимизированные материалы из реальных онлайн-консультаций телемедицинского сервиса.
Описание датасета
Поля данных
Каждый вопрос в датасете содержит следующие поля:
instruction[str] — Промпт-инструкция для модели, содержащая шаблон для вставки элементов вопроса.inputs— Вводные данные, формирующие задание для модели.question[str] — Текст вопроса.image[str] — Путь к файлу с изображением, к которому относится вопрос.option_a[str] — Вариант ответа A.option_b[str] — Вариант ответа B.option_c[str] — Вариант ответа C.option_d[str] — Вариант ответа D.option_e[str] — Вариант ответа E.option_f[str] — Вариант ответа F.option_g[str] — Вариант ответа G.
outputs[str] — Правильный ответ на вопрос.meta— Метаданные, относящиеся к тестовому примеру, но не используемые в вопросе (скрытые от тестируемой модели).id[int] — Номер-идентификатор вопроса в датасете.categories— Категории признаков, характеризующих тестовый пример.question_type[str] — Категория вопроса.question_text[str] — Тип задачи по тексту вопроса.question_source[str] — Источник вопроса: human, если вопрос написан человеком, или generated, если вопрос сгенерирован с помощью модели o4-mini.
image— Метаданные, относящиеся к изображению.synt_source[list] — Источники, с помощью которых сгенерированы или воссозданы данные для формирования вопроса, в том числе названия генеративных моделей.source[list] — Информация о происхождении изображения — согласно классификации изображений для датасетов MERA.type[list] — Тип изображения — согласно классификации изображений для датасетов MERA.content[list] — Содержание изображения — согласно классификации изображений для датасетов MERA.context[list] — Сопроводительный контекст, присутствующий на изображении, — согласно классификации изображений для датасетов MERA.
rows[int] — Количество строк в таблице на изображенииcolumns[int] — Количество столбцов в таблице на изображении.
Оценка
Метрики
Для агрегированной оценки ответов моделей используются следующие метрики:
- `Exact match`: Метрика Exact match вычисляет среднее по оценкам всех обработанных вопросов, где оценка имеет значение 1, если предсказанная строка точно совпадает с правильным ответом, и 0 в остальных случаях.
Human baseline
Human baseline — это оценка усреднённых ответов людей на вопросы бенчмарка. Оценка проводится по тем же метрикам, что и для моделей.
Human baseline формировался на основе независимой разметки на платформе TagME, с перекрытием 5. Асессоров просили ответить на полученные вопросы, в инструкцию были добавлены примеры с пояснениями (те же, что и для few-shot). В качестве финального предсказания использовалось majority vote среди ответов асессоров (не менее 3 совпадений из 5), метрика составила 93.9%. В 11 сэмплах (3.35% от всех данных) не удалось набрать 3 совпадающих ответа, поэтому они не учитывались при оценке.
Результаты оценки:
- Exact match – 0.91
Мотивация
Датасет LabTabVQA создан для оценки способности мультимодальных моделей работать с табличной информацией, представленной в виде изображений, на русском языке. Его ключевая цель — оценить способность мультимодальных моделей понимать структуру таблиц, интерпретировать их содержимое, распознавать форматирование, соотносить информацию и делать выводы, пользуясь лишь общими знаниями моделей.
Методология сбора датасета и построения вопросов не замкнута на определённом домене и может быть применена для расширения набора данных таблицами из смежных областей знаний. Датасет позволит расширить русскоязычные бенчмарки классом задач для оценки способностей моделей анализировать таблицы с точки зрения распознавания содержимого, работы со сложной структурой, иерархией, интерпретацией данных в end-to-end-сценариях.
Создание датасета
Для создания датасета использовались 697 реальных изображений с платформы телемедицинских консультаций.
При помощи модели GPT-4o Mini мы разметили изображения по двум бинарным критериям:
- наличие таблицы на изображении;
- фото или скриншот.
Отбор прошло 339 изображений, сбалансированных по типу изображения и размеру таблицы (который также оценивался с помощью GPT-4o Mini). Для 138 примеров вопросы были составлены экспертами, для остальных — 201 пример — вопросы были получены при помощи AI-агентной системы, состоящей из следующих компонент:
1. QuestionGenerator (GPT-o4 Mini) на основе изображения и категории вопроса генерирует вопрос-кандидат с семью вариантами ответа.
2. QuestionQualifier (GPT-o4 Mini) фиксирует правильный ответ из семи предложенных либо запрашивает перегенерацию ответов у QuestionGenerator, если не находит правильного варианта.
3. Solver-ы (GPT-4o Mini) трёх уровней сложности (определяемых промптами) отвечают на вопрос и дают обратную связь с пояснением логики ответа.
4. FeedbackEvaluator (GPT-o4 Mini) анализирует ответы и фидбэк Solver-ов и принимает решение: утвердить вопрос или отправить его на перегенерацию (возврат к шагу 1).
Сгенерированные примеры валидировались через платформу TagMe (с перекрытием в 3 мнения/ответа) по следующим критериям:
- вопрос составлен по предоставленной на изображении таблице;
- вопрос не требует специфических доменных знаний для ответа (всё есть на изображении/таблице);
- на вопрос невозможно ответить без использования таблицы/изображения.
Аналогично при помощи асессоров выбирался правильный вариант ответа. Правильным ответом считались:
- ответ, предложенный системой генерации вопросов, если с ним согласилось хотя бы 2 из 3 асессоров;
- ответ, выбранный хотя бы 2 из 3 разметчиков, не совпадающий с предложенным системой создания вопросов, но дополнительно валидированный мета-асессором.
В связи с особенностями выбранной методологии генерации вопросов датасет и задачи могут быть предвзятыми в сторону семейства моделей GPT-o4.
Авторы
Амина Мифтахова, Иван Свиридов
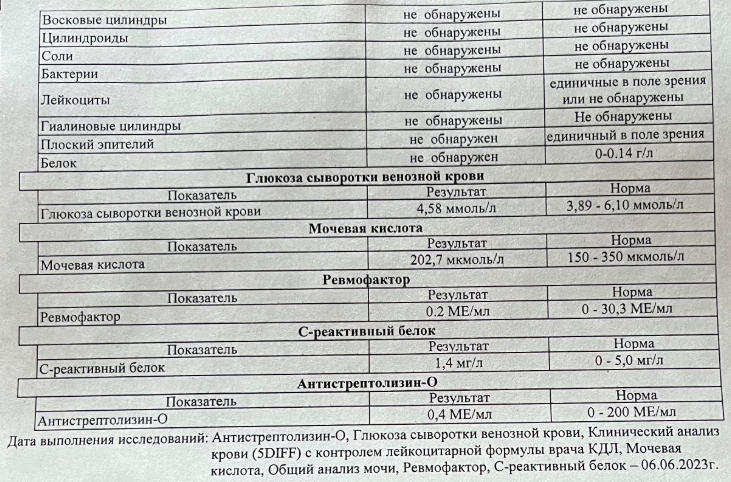 "question": "Для скольких показателей нормальные значения указаны в виде числового диапазона?"
},
"outputs": "B",
"meta": {
"id": 346,
"categories": {
"question_type": "Формат и оформление данных - Формат значений",
"question_text": "Подсчёт количества",
"question_source": "human"
},
"image": {
"synt_source": [],
"source": [
"photo"
],
"type": [
"systematic"
],
"content": [
"info"
],
"context": [
"no_context"
]
},
"rows": 11,
"columns": 3
}
}
```
"question": "Для скольких показателей нормальные значения указаны в виде числового диапазона?"
},
"outputs": "B",
"meta": {
"id": 346,
"categories": {
"question_type": "Формат и оформление данных - Формат значений",
"question_text": "Подсчёт количества",
"question_source": "human"
},
"image": {
"synt_source": [],
"source": [
"photo"
],
"type": [
"systematic"
],
"content": [
"info"
],
"context": [
"no_context"
]
},
"rows": 11,
"columns": 3
}
}
```
 GitHub
GitHub