
How MERA works
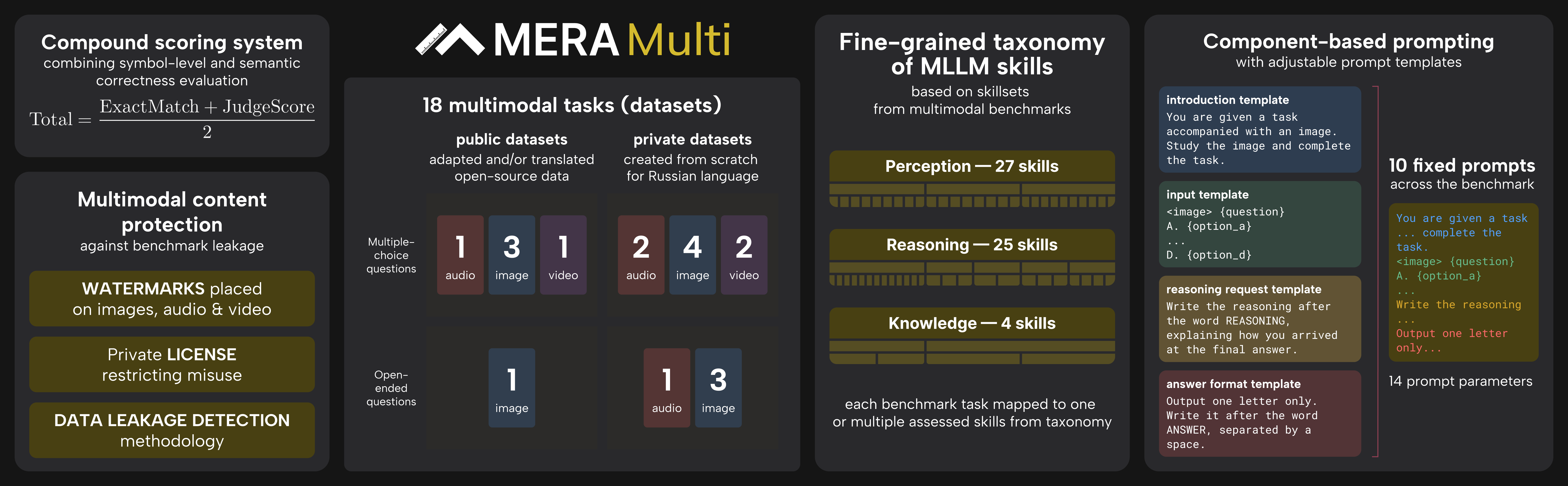
MERA is an independent benchmark for evaluating LLM in Russian. The benchmark tasks test knowledge of the world and the ability to solve problems in text form, as well as work with code (MERA Code).MERA Multi expands the benchmark with tasks for understanding images, audio, and video. The 18 new tasks follow the methodology of the main benchmark and were developed by experts specifically for MERA.The website features a leaderboard (rating) of models based on the quality of solutions to a fixed set of tasks, both separately by modality and for the full multimodal benchmark (Multi). Model measurements are performed according to a standardized procedure with fixed prompt and parameter configurations.The project is supported by the AI Alliance, leaders of the industry, and academic partners engaged in language model research
License and data leak
Images, audio, and video are protected by license: tasks can only be used for testing models, not for training
How is the measurement set up?
To ensure correct comparison of models, experts have developed:
— A set of independent universal prompts – each question in the task is accompanied by exactly one prompt from a pre-prepared set;
— Strict requirements for the output format – all models receive the same instructions for the structure of the answer;
— Fixed generation conditions – a ban on modifying prompts, generation parameters and a few-shot examples during testing.This approach eliminates biases in estimates:
— Averaging over different props minimizes the impact of wording specifics;
— Uniform conditions for all models exclude "adjustment" for specific architectures.
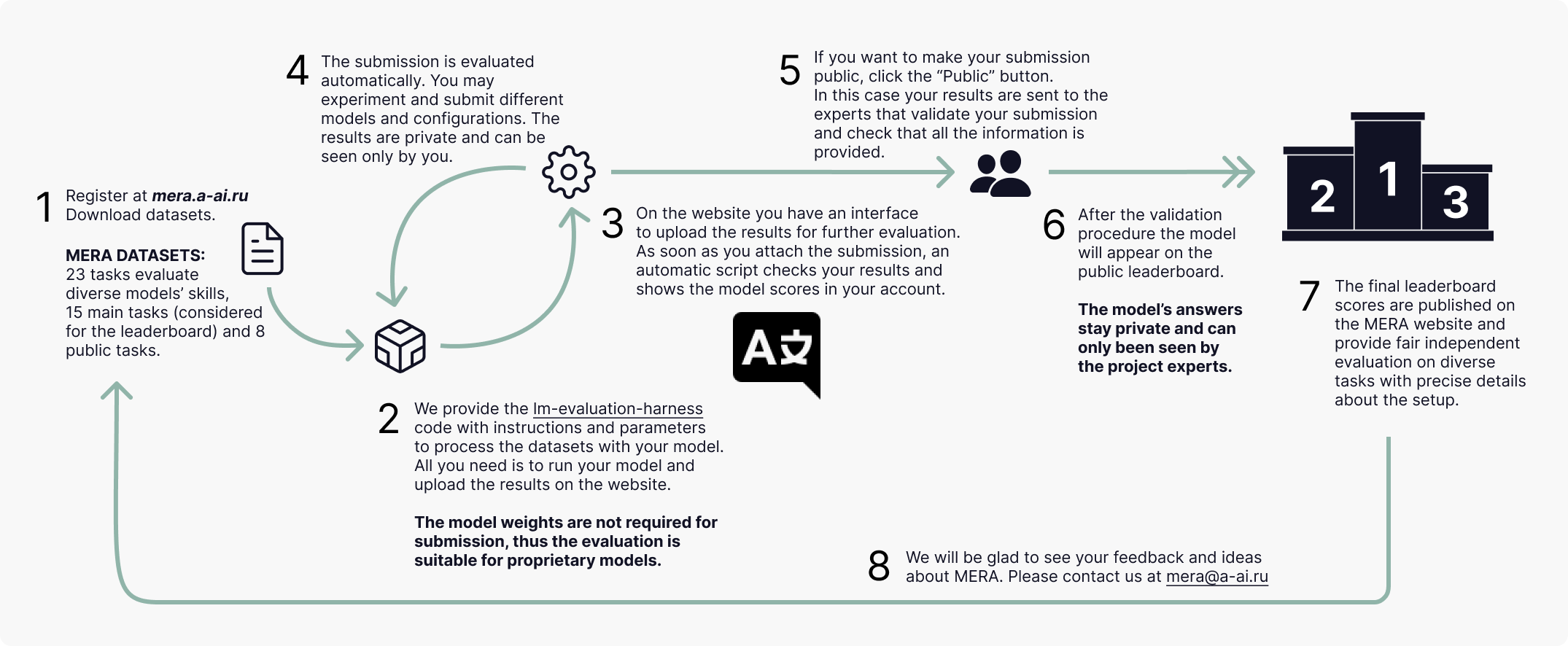
The code base for evaluation on the MERA Code benchmark is developed on the basis of the international code base LM Evaluation Harness, which allows evaluating a model in a generative format. After the user has tested their model, the code base produces a ZIP archive — this is the participant's submission, which is then uploaded to the site. The submission with the results of the models is automatically tested and compared with the gold answers. For this, environments and test environments for different languages are raised. Submission processing can take several hours. Then, the participant sees the results of the model evaluation on the benchmark in their personal account. At the participant's request, the evaluation result can be sent to the public leaderboard
How are prompta set up for tasks?
Task prompts are consistent and fixed across the entire benchmark. They take into account the use of grammatical variations specific to Russian, notably the politeness register governed by the T-V distinction and explicit/implicit declaration of the response format to test the model's robustness to such variations.We recommend specifying a system prompt during evaluation; it will be common to all tasks
Skill taxonomy
The MERA Multi skills taxonomy offers a systematic approach to assessing the MLLM abilities required to solve problems with multimodal content. This approach breaks down any task into a limited and manageable set of key skills, making the taxonomy both comprehensive and easily understandable.The approach is based on representing a language model as a system with three components: input, internal state, and output. Based on this, three basic skill groups are identified — Perception, which is responsible for input data; Reasoning; and Knowledge, which are the internal characteristics of the model. These skills serve as the foundation of the entire taxonomy. The remaining skills are arranged in a hierarchical structure, gradually becoming more refined and specialized at each subsequent level. MERA Code also includes another basic block — Generation
Useful links
 Repository:
Repository:
 HF datasets:
HF datasets:
 Research paper
Research paper
 Technical support:
Technical support:
 FAQ
FAQ
FAQ
What is MERA Multi?
MERA Multi is a multimodal task benchmark within the independent MERA benchmark. The 18 instructional tasks include image and video analysis, speech and non-speech sound recognition. These skills are tested in free-form short-answer and multiple-choice tasks
How do I add my result to the public leaderboard?
By default, uploaded submissions remain private. To make the result public, check the "Publish" option. After that, MERA Code administrators will receive a request for review. If the submission meets the requirements, it will be approved and you will receive an email notification. Your model will appear on the leaderboard. If necessary, you may be contacted for clarification of details.To be accepted for publication, a submission must contain:
— Results for all tasks;
— Description of the solution (at least a link to the model, article, or model description);
— A complete list of resources used (data sources, model parameters, and other key details).
If you update your submission, the review process will be repeated. Before sending, make sure all the details are correct and the description is as detailed as possible
How do I add my result to the public leaderboard?
To evaluate your model on the MERA benchmark, collect the results of its runs for each dataset.
— Use the official evaluation code base from the official project repository. Add your model to the code and run the test according to the instructions. Do not change the startup parameters!
— As a result of the code, you will receive a submission in the form of a ZIP archive for uploading to the site. Do not change the name of the files or ID in the responses in the submissions, otherwise the evaluation result will be incorrect.
— Register on the website. Create a new submission in your account. Add as much information about your model as possible, and provide links to your solution (article or code on github). This is important! In order to get on the leaderboard, we need to make sure that your result is fair. We believe that science should be reproducible!
— Attach a ZIP archive. Send the submission to the system. In a few hours, the automatic script will process the data, and the result will be available in your personal account
Can I test my proprietary model on MERA?
Yes, you can! We have prepared code for evaluation via the lm-harness framework, including for API models. Run testing of your model and upload the archive with the results to the site. The scores will be available to you in your personal account and will remain closed to other users. If you want to place your model on a public leaderboard, please provide as much information about it as possible when submitting:
— training process,— data used,
— architecture,
— system parameters.
This information will help the community understand and reproduce your system. The submission is moderated by experts who can contact you for further details.
Important: even if your model is published in the ranking, its answers will remain available only to experts and will not be disclosed to the general public
Is it possible to make an anonymous submission on a public leaderboard?
Yes, you can. The leaderboard displays the names of teams and models, but you can make an anonymous account. The main thing is that participants and administrators can contact you
What license are the datasets available under?
Datasets created using open-source data inherit the original license (mostly CC-BY-4.0). Images, audio, and video collected specifically for MERA Multi are protected by a special MERA license: the materials may only be used for model testing, not training. Such images, audio, and video are watermarked, preventing their "accidental" use in model training.The materials are permitted for educational use, but only for model evaluation
Why can't I see the results of my model/submission?
If you've submitted a submission for evaluation, please wait first — model processing may take some time.Then check that your submission has loaded in the system — it will appear in your list of submissions. Otherwise, an error message will appear.In other cases, if your submission fails for some reason, please contact us at mera@a-ai.ruIf the submission is invalid, the system will display a text description of the error, which covers cases such as:— The uploaded ZIP archive is missing one of the required files for the tasks.— There's something wrong with the metadata (for example, you're missing an ID). All IDs for each task in the JSON are required and start with 0. Check that all IDs match the test set
I found a bug, I have suggestions and comments!
You can contact us by email at mera@a-ai.ru. For suggestions and errors in the evaluation code or data, please create Issues in our official GitHub.For quick communication, there is a Telegram chat for technical support
How are the results aggregated on the leaderboard?
We have introduced three key metrics that reflect model quality:
— Attempted Score — quality on solved tasks: modality weights are recalculated only across those tasks the model actually attempted.
— Coverage — the proportion of processed tasks within the leaderboard.
— Total Score — the final score that determines the ranking, calculated as Total Score = Attempted Score × Coverage.
The Total Score is used to rank models on the leaderboards. This approach already enables the creation of a multimodal model ranking that accounts for different task types. In the future, it will allow for seamless benchmark expansion by adding new and more complex scenarios without compromising compatibility with existing results.
To which leaderboard should I submit my model?
For the multimodal version of **MERA**, we introduced four independent leaderboards:
1. Images — tasks focused on analyzing photos, illustrations, and screenshots.
2. Audio — tasks involving speech, music, and ambient sound understanding.
3. Video — tasks for analyzing video content without audio.
4. Multi — a unified leaderboard combining tasks from all modalities.
Participants can choose which leaderboard to submit their model to.
To qualify, a submission only needs to include at least one task from the selected leaderboard.
Partial submissions are allowed to ensure that evaluation remains fair and transparent.

 GitHub
GitHub