
<Modern LLM Code Benchmark>
| {{ task.title }} |
|---|
| {{ getTaskScore(submit, task) }} |
There are no suitable results
The new standard for independent evaluation of models
Quick and accurate evaluation of models in a couple of steps

The expert approach
The methodology was created by industry and academic experts

Multitasking and multilingualism
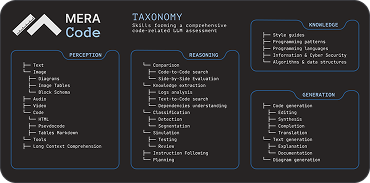
The variety of code evaluating tasks from code review to unit testing for 8 programming languages

Accessibility
Access to open source, fixed prompts and launch parameters
Partners and participants







What we suggest
Quantitative metrics and qualitative analysis, fixed launch parameters and a unified prompt methodology for transparent and detailed evaluation
Independent leaderboard for evaluating modern models
- Comparison of the latest frontier AI models
- Identifying the best models in specific areas and knowledge
- A useful tool for developers to analyze and select the optimal model for their needs

Tasks for any level of expertise
A catalog of code problems with detailed information about the test and its creation

Manage submissions in your personal account
- Quick registration
- All active submissions at hand
- Detailed assessment results by tasks

A Transparent Methodology for Testing Generative Models
Read the detailed description of the benchmark creation methodology
Evaluate models in minutes, not weeks
Submit submissions, track results, and compare models in one place


Uniting leaders for the future of technology
The Alliance for Artificial Intelligence is a unique organization created to unite the efforts of leading technology companies, researchers and experts. Our mission is to accelerate the development and implementation of artificial intelligence in the key areas, such as education, science and business.
Learn More About The Alliance
 GitHub
GitHub