
Task description
UniScienceVQA is a multimodal dataset consisting of tasks designed to assess expert knowledge in various fields of science (fundamental, social, and applied sciences, cultural studies, business, health, and medicine). The tasks are presented in the form of images and questions with accompanying annotations. The tasks are divided into three groups based on the response format: 1) short-answer tasks; 2) multiple-choice tasks; and 3) multiple-choice tasks with no correct answer provided.Описание датасета
Data description
instruction[str] — Instruction prompt template with question elements placeholders.inputs— Input data that forms the task for the model.image[str] — Path to the image file related to the question.question[str] — Text of the question.annotation[str] — The format of the response;
outputs[str] — The correct answer to the question.meta— Metadata related to the test example, not used in the question (hidden from the tested model).id[int] — Identification number of the question in the dataset.categories— Categorial features characterizing the test example.subdomain[str] — Job subdomain.type_answer[str] — Answer option: short answer or select the correct answer.
image— Image metadata.source[str] — Information about the origin of the image — according to the image classification for MERA datasets.-
type[str] — Image type — according to the image classification for MERA datasets. content[str] — Image content — according to the image classification for MERA datasets.
Evaluation
Metrics
Metrics for aggregated evaluation of responses:
- `Exact match`: Exact match is the average of scores for all processed cases, where a given case score is 1 if the predicted string is the exact same as its reference string, and is 0 otherwise.
Human baseline
Human baseline is an evaluation of the average human answers to the benchmark questions. The evaluation is carried out using the same metrics as for the models.
For all questions in the dataset, annotator answers were obtained on a crowd-sourcing platform with an overlap of 5. Free-form answers were normalized (case, spaces) for comparison with the reference. The aggregated answer was considered to be the one that was chosen by the majority (majority vote).
Evaluation results:
- Exact match – 0.13
Motivation
The dataset is an open collection of tasks designed to evaluate a model's ability to understand elements of images from university curricula and professional domains. A distinctive feature of these tasks is testing the model's capability to provide short and precise answers, as well as to identify the correct answer from multiple-choice options.
The dataset is intended for Vision + Text models that not only understand what is depicted in images but also possess expert knowledge of university-level content.
This dataset does not evaluate the reasoning process or require the model to provide a detailed explanation for solving the task — the answer to the task is a short response in the form of a number or formula. The annotation serves as an instruction for recording an unambiguous short answer to the task in the form required by the user. Therefore, Accuracy is used as the evaluation metric.
Dataset creation
The dataset consists of 25 subdomains, and for data collection in each subdomain, a group of experts with in-depth knowledge in the respective field was involved. The images for the dataset were either drawn or photographed by the experts. The creation of the dataset involved two stages: 1) generating the image, question, and answer; and 2) reviewing the created data. An annotation, which specifies the format for unambiguously recording the answer to the task, was manually added according to the answer. Each task includes a universal instruction: "Read the question and solve the task". As a result, 200-400 tasks were collected for each subdomain.
Contributors
Alexander Kapitanov, Petr Surovtsev
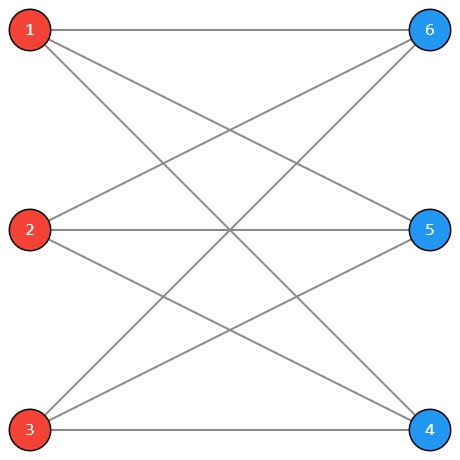 "question": "Какой порядок группы автоморфизмов изображённого графа?",
"annotation": "В ответе напишите только число."
},
"outputs": "72",
"meta": {
"id": 1633,
"categories": {
"subdomain": "Computer science and Programming",
"type_answer": "short answer"
},
"image": {
"source": "photo",
"type": "visual",
"content": "riddle"
}
}
}
```
"question": "Какой порядок группы автоморфизмов изображённого графа?",
"annotation": "В ответе напишите только число."
},
"outputs": "72",
"meta": {
"id": 1633,
"categories": {
"subdomain": "Computer science and Programming",
"type_answer": "short answer"
},
"image": {
"source": "photo",
"type": "visual",
"content": "riddle"
}
}
}
```
 GitHub
GitHub