
Task description
**NaturalScienceQA** is a multimodal question-answering dataset on natural sciences with basic questions from the school curriculum, based on the English dataset [ScienceQA](https://scienceqa.github.io/index.html#home). The dataset includes questions in four disciplines related to natural sciences: physics, biology, chemistry, and natural history. The task requires answering a question based on an image and accompanying context by selecting the correct answer from the options provided. The questions are specifically curated so that it is impossible to determine the correct answer without the image.
**Note:** A feature of the dataset is that the images used in the tasks may be of relatively low resolution. Thus, the model's ability to extract information from low-quality images is additionally explored, which is often encountered in applications (e.g., when a user sends a poor-quality screenshot).
Data description
Data fields
Each dataset question includes data in the following fields:
instruction[str] — Instruction prompt template with question elements placeholders.inputs— Input data that forms the task for the model.image[str] — Path to the image file related to the question.context[str] — A supportive context used along with the image to solve the task.question[str] — Text of the question.option_a[str] — Answer option A.option_b[str] — Answer option B.option_c[str] — Answer option C.option_d[str] — Answer option D.
outputs[str] — The correct answer to the question.meta— Metadata related to the test example, not used in the question (hidden from the tested model).id[int] — Identification number of the question in the dataset.categories— Categorial features characterizing the test example.domain[str] — Categorial features characterizing the test example.subdomain[str] — A subdomain of the sample; due to the imbalance, this field should not be used for aggregation; it is provided solely for informational purposes.
Evaluation
Metrics
Metrics for aggregated evaluation of responses:
- `Exact match`: Exact match is the average of scores for all processed cases, where a given case score is 1 if the predicted string is the exact same as its reference string, and is 0 otherwise.
Human baseline
Human baseline is an evaluation of the average human answers to the benchmark questions. The evaluation is carried out using the same metrics as for the models.
These tasks were presented to two groups: one consisting of untrained participants (overlap 5) and the other of domain experts (overlap 3). The aggregated answer was considered to be the one chosen by the majority (majority vote).
Evaluation results:
- Exact match – 0.94
- Exact match (expert) – 0.99
Motivation
The NaturalScienceQA dataset is aimed at evaluating the reasoning abilities of AI models in a multimodal environment. Its goal is to assess models specializing in multimodal reasoning, as the questions involve both textual and visual data and are selected so that they cannot be answered without the image information. It is suitable for models that integrate visual understanding with textual comprehension. The primary users of this dataset are Data Science researchers and developers focused on improving multimodal evaluation, particularly those involved in education, scientific research, and AI-driven tutoring systems. Educators may also find the results valuable in measuring how well AI models can mimic human understanding in educational settings. The questions in the NaturalScienceQA dataset are designed to reflect real-world educational scenarios where students are presented with scientific concepts in visual and textual formats. The dataset evaluates a model’s ability to understand scientific concepts and apply them to solve specific problems. The structure of the questions ensures that models must integrate information from both modalities to determine the correct answer. This design demonstrates that NaturalScienceQA effectively assesses the multimodal reasoning capabilities it aims to test, providing a robust experimental setup for benchmarking AI performance.
Dataset creation
NaturalScienceQA was created based on the English [ScienceQA](https://scienceqa.github.io/index.html#home) dataset, a question-answering dataset covering a wide range of scientific disciplines. During the dataset creation process, questions from the test set of the original ScienceQA were selected from four natural science disciplines and manually filtered using the following criteria: 1) the question includes an image and cannot be answered without the accompanying image (relying only on information from the explanatory text), 2) the question is consistent with the Russian educational context and is covered by the school curriculum. Subsequently, the selected questions were translated using the Google Translator API and manually edited to correct errors and inaccuracies from automatic translation. Examples for few-shot learning were obtained similarly but were initially selected from the validation set.
Contributors
Maria Tikhonova
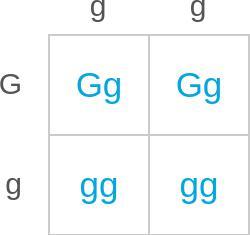 "context": "В этом отрывке описана особенность роста у растений розы. Вьющийся рост и плетистый рост — это разные типы роста у розы. Вьющиеся растения имеют длинные, изгибающиеся стебли, похожие на лианы. Такие растения могут расти вверх, покрывая заборы или стены. Розы с плетистой формой роста держатся у земли. Такие растения образуют низкие кусты или кустарники. В группе розовых растений некоторые особи имеют вьющийся рост, а другие — плетистый. В этой группе ген, отвечающий за признак формы роста, имеет два аллеля. Аллель вьющегося роста (G) доминирует над аллелем плетистого роста (g). В этой решётке Пеннета показано скрещивание двух растений розы.",
"question": "Каково ожидаемое соотношение потомства с плетистым ростом к потомству с кустовым ростом? Выберите наиболее вероятное соотношение.",
"option_a": "4:0",
"option_b": "0:4",
"option_c": "2:2",
"option_d": "3:1"
},
"outputs": "C",
"meta": {
"id": 61,
"categories": {
"domain": "biology",
"subdomain": "Genes to traits"
}
}
}
```
"context": "В этом отрывке описана особенность роста у растений розы. Вьющийся рост и плетистый рост — это разные типы роста у розы. Вьющиеся растения имеют длинные, изгибающиеся стебли, похожие на лианы. Такие растения могут расти вверх, покрывая заборы или стены. Розы с плетистой формой роста держатся у земли. Такие растения образуют низкие кусты или кустарники. В группе розовых растений некоторые особи имеют вьющийся рост, а другие — плетистый. В этой группе ген, отвечающий за признак формы роста, имеет два аллеля. Аллель вьющегося роста (G) доминирует над аллелем плетистого роста (g). В этой решётке Пеннета показано скрещивание двух растений розы.",
"question": "Каково ожидаемое соотношение потомства с плетистым ростом к потомству с кустовым ростом? Выберите наиболее вероятное соотношение.",
"option_a": "4:0",
"option_b": "0:4",
"option_c": "2:2",
"option_d": "3:1"
},
"outputs": "C",
"meta": {
"id": 61,
"categories": {
"domain": "biology",
"subdomain": "Genes to traits"
}
}
}
```
 GitHub
GitHub