
Task description
ruMathVQA is a multimodal dataset consisting of school math problems presented in the form of images and annotated questions to record the answer in an unambiguous form.
Data description
Data fields
Each dataset question includes data in the following fields:
instruction[str] — Instruction prompt template with question elements placeholders.inputs— Input data that forms the task for the model.image[str] — Path to the image file related to the question.annotation[str] — The required response format;
outputs[str] — The correct answer to the question.meta— Metadata related to the test example, not used in the question (hidden from the tested model).id[int] — Identification number of the question in the dataset.categories— Categorial features characterizing the test example.topic[str] — The subject and the grade of the task ex. [mathematics | geometry] n grade;
image— Image metadata.source[str] — Information about the origin of the image — according to the image classification for MERA datasets.type[str] — Image type — according to the image classification for MERA datasets.content[str] — Image content — according to the image classification for MERA datasets.
Evaluation
Metrics
Metrics for aggregated evaluation of responses:
- `Exact match`: Exact match is the average of scores for all processed cases, where a given case score is 1 if the predicted string is the exact same as its reference string, and is 0 otherwise.
Human baseline
Human baseline is an evaluation of the average human answers to the benchmark questions. The evaluation is carried out using the same metrics as for the models.
Tasks were solved separately by a group of experts (overlap 3) and a group of annotators without special training (overlap 5), who correctly completed at least 80% of the test tasks from grades 5 and 6. The tasks had to be solved within a limited time: 4 minutes for 5th and 6th grades, 5 minutes for 7th grade, 6 minutes for 8th grade, and 7 minutes for 9th grade. Participants were asked to solve the tasks without using the internet or neural network models and to record their answers in the required format. Free-form answers were normalized (case, spaces) for comparison with the reference. The aggregated answer was considered to be the one that was chosen by the majority (majority vote).
Evaluation results:
- Exact match – 0.93
- Exact match (expert) – 0.95
Motivation
The dataset is an open database of tasks for testing the model's ability to understand pictorial elements from school mathematics and geometry and apply knowledge of school mathematics grades 5-6 and geometry grades 7-9. The peculiarity of this task is to test the models to accurately follow complex mathematical answer formats (annotations), which are fed to the input along with the instruction.
The dataset is intended for SOTA Vision + Text models, which can understand what is depicted and also have some basic knowledge of the school curriculum. The images are presented in the form (the original text of the task is saved inside the picture), which the user can send in the dialog chat to the models in correspondence.
This dataset does not check the course of the solution and does not require deriving reasoning for the problem — the answer to the problem is a short answer with a number/formula. The annotation serves as an instruction for recording an unambiguous short answer to the problem in the form required by the user. Therefore, Accuracy is used as a metric.
Dataset creation
A group of experts with basic knowledge of mathematics was selected for the dataset collection stage. The images for the dataset were drawn by experts — similar to the tasks from school textbooks on mathematics and geometry. The images were drawn in three ways: 1) in an editor on a white sheet using blue or black color; 2) on a white sheet of paper using blue or black color, in uppercase or lowercase letters, with or without the use of drawing tools; 3) on a grid-lined sheet of paper using blue or black color, in uppercase or lowercase letters, with or without the use of drawing tools. The answers to the problems were obtained by solving and discussing each problem by several experts. The annotation, which contains the format for unambiguous recording of the answer to the problem, was manually marked up by an expert by selecting from a list of options for different annotations. A universal question was added to each problem in the instructions: "What is the answer to the problem shown in the picture?"
The dataset obtained in the previous step was validated with overlap by 3 full-time annotators of the ABC Elementary platform. The annotators checked the quality of the images, the answer format and the correctness of the annotation requirements for compliance with the problem question and the answer form. Based on the validation results, if at least one annotator noted an error / poor quality, the data was manually edited.
Contributors
Alexander Kapitanov, Petr Surovtsev
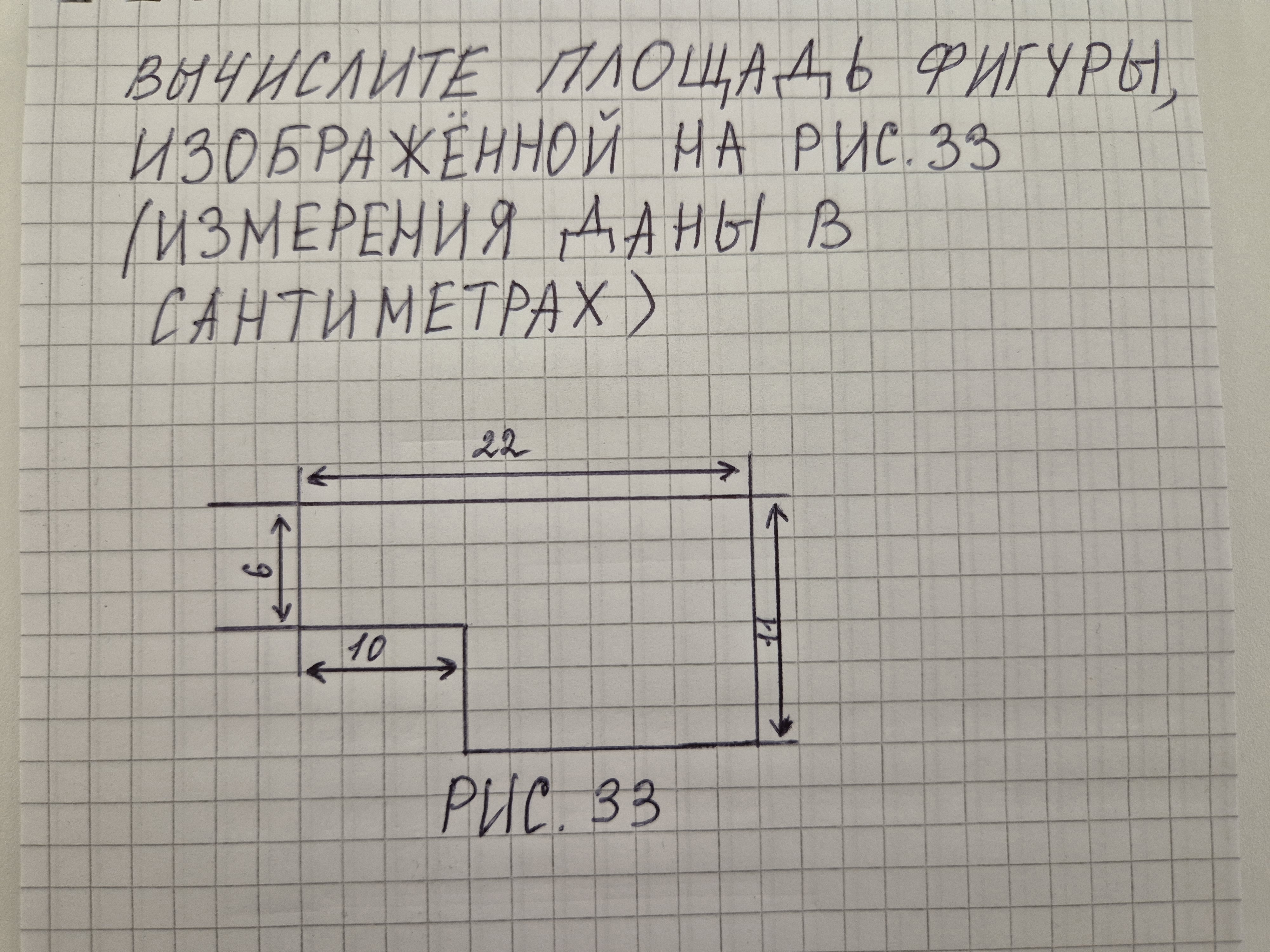 "annotation": "Запишите ответ одним целым числом в см$^2$ без указания единиц измерения."
},
"outputs": "192",
"meta": {
"id": 1,
"categories": {
"topic": "mathematics 5th grade"
},
"image": {
"source": "photo",
"type": "visual",
"content": "riddle"
}
}
}
```
"annotation": "Запишите ответ одним целым числом в см$^2$ без указания единиц измерения."
},
"outputs": "192",
"meta": {
"id": 1,
"categories": {
"topic": "mathematics 5th grade"
},
"image": {
"source": "photo",
"type": "visual",
"content": "riddle"
}
}
}
```
 GitHub
GitHub