
Как работает MERA
Современные кодовые языковые модели и модели общего назначения (ChatGPT, Claude, Qwen, YandexGPT, GigaChat и др.) развиваются быстрыми темпами, но их сравнение затруднено из-за отсутствия единой методологии оценки. Ключевая проблема — разрозненность тестовых задач и условий замеров: разные датасеты, промптинговые стратегии и метрики. Кроме того, оценка часто проводится самими разработчиками, что ставит под сомнение объективность результатов.
Мы предлагаем открытый инструкционный бенчмарк для русскоязычных моделей для задач работы с кодом, основанный на фиксированном наборе тестов с четкими критериями. Наш подход обеспечивает:
— Стандартизированные конфигурации (промпты, параметры генерации);
— Экспертно составленные задачи, отражающие реальные сценарии использования при работе с кодом;
— Прозрачную методику оценки, исключающую конфликт интересов.
Проект поддерживается Альянсом ИИ, индустриальными лидерами и академическими исследователями, что гарантирует независимость и релевантность бенчмарка для развития кодовых моделей.
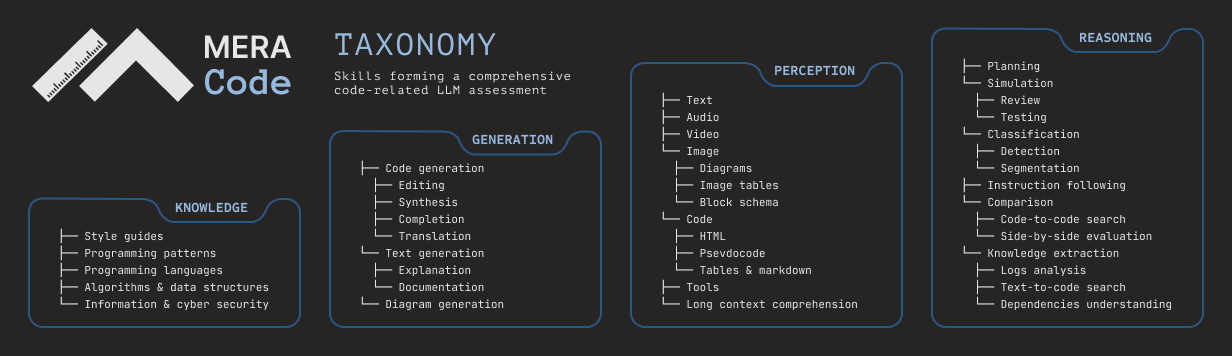
Таксономия MERA CODE предлагает системный подход к оценке кодовых способностей моделей, сосредоточенный на навыках программирования, необходимых для решения конкретных задач. Такой подход позволяет разбить любую задачу на ограниченный и управляемый набор ключевых навыков, что делает таксономию одновременно всеобъемлющей и доступной для понимания.
В основе подхода лежит представление языковой модели как системы с тремя компонентами: входными данными, внутренним состоянием и выходом. Исходя из этого, выделяются четыре базовых навыка — Восприятие (Perception), отвечающее за входные данные, Логическое мышление (Reasoning) и Знания (Knowledge) являющиеся внутренними характеристиками модели, и Генерация (Generation) отвечающая за выходные данные, — которые служат фундаментом всей таксономии. Остальные навыки выстраиваются в иерархическую структуру, постепенно уточняясь и специализируясь на каждом следующем уровне.
Для обеспечения корректного сравнения моделей эксперты разработали:
— Набор независимых универсальных промптов – каждый вопрос в задаче сопровождается строго одним промптом из заранее подготовленного набора;
— Жесткие требования к формату вывода – все модели получают одинаковые инструкции по структуре ответа;
— Фиксированные условия генерации – запрет на модификацию промптов, параметров генерации и few-shot примеров во время тестирования.Такой подход устраняет смещения в оценках:
— Усреднение по разным промптам минимизирует влияние специфики формулировок;
— Единые условия для всех моделей исключают "подстройку" под конкретные архитектуры.
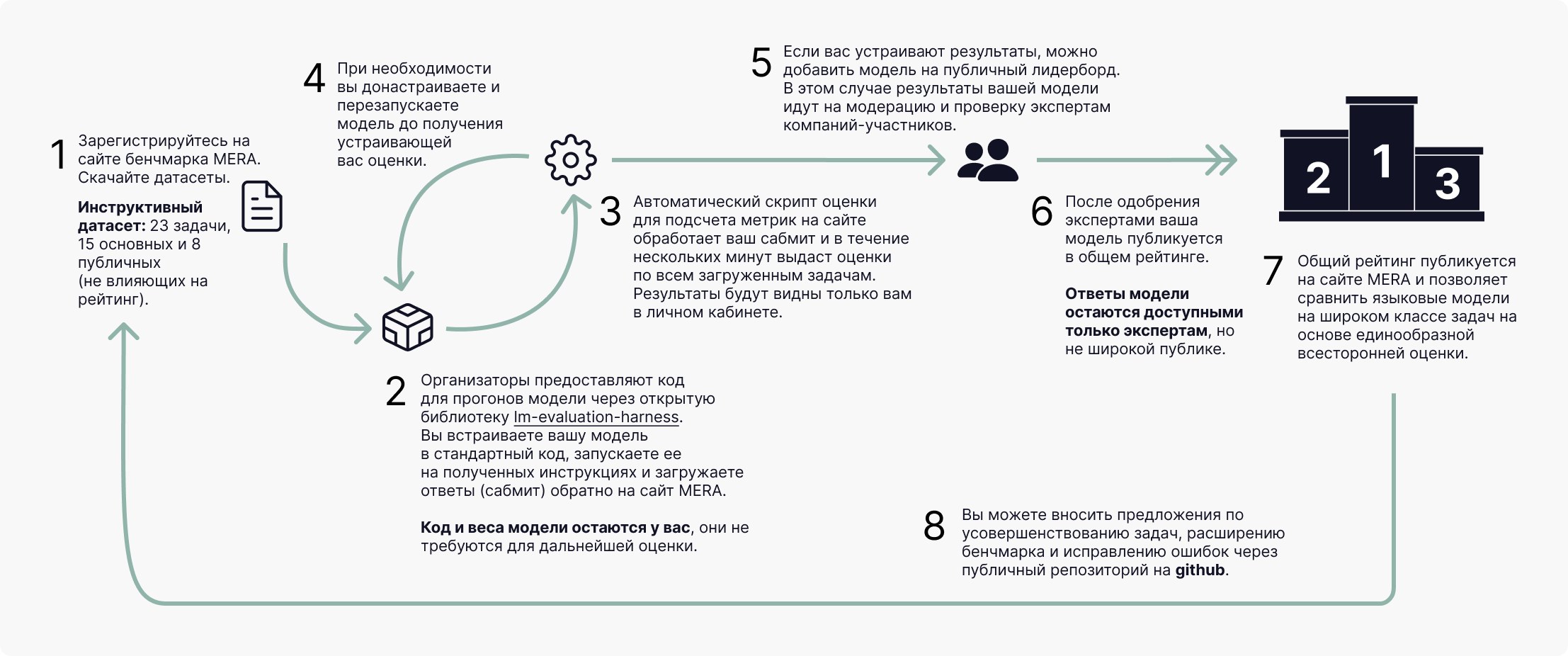
Кодовая база для оценки на бенчмарке MERA Code разработана на основе международной кодовой базы LM Evaluation Harness, которая позволяет оценивать модель в генеративном формате. После того, как пользователь протестировал свою модель, кодовая база выдает ZIP-архив - это сабмит участника, который далее загружается на сайт. Сабмит с результатами моделей автоматически тестируется и сравнивается с золотыми ответами. Для этого поднимаются окружения и тестовые среды для разных языков. Обработка сабмита может занимать несколько часов. Далее, участник видит результаты оценки моделей на бенчмарке в личном кабинете.
 Репозиторий:
Репозиторий:
 GitVerse:
GitVerse:
 Публикация:
Публикация:
 HF datasets:
HF datasets:
 Чат техподдержки:
Чат техподдержки:
 FAQ
FAQ
Вопросы и ответы
Что такое MERA?
MERA (Multimodal Evaluation for Russian-language Architectures) — независимый бенчмарк для оценки современных больших языковых моделей на русском языке, разработанный и поддерживаемый исследователями из индустрии и академии. Он включает 23 инструктивные задачи, охватывающие различные типы задач и домены.
Как использовать бенчмарк MERA?
Чтобы оценить свою модель на бенчмарке MERA, соберите результаты её прогонов для каждого датасета, включая диагностические.
- Воспользуйтесь официальной кодовой базой оценки из официального репозитория проекта. Добавьте свою модель в код и запустите тестирование согласно инструкции. Не изменяйте параметры запуска!
- В результате работы кода вы получите сабмит в правильном формате для заливки на сайт. Не меняйте название файлов или ID в ответах в сабмитах, иначе результат оценки будет некорректный.
- Зарегистрируйтесь на сайте. В личном кабинете создайте новый сабмит. Добавьте как можно больше информации о своей модели, и укажите ссылки на своё решение (статью или код на github). Это важно! Для того, чтобы попасть на лидерборд, нам нужно убедиться, что ваш результат честный. Мы верим, что наука должна быть воспроизводимой!
- Прикрепите ZIP архив. Отправьте сабмит в систему. Через несколько минут автоматический скрипт обработает данные, и результат станет доступен в личном кабинете.
Дополнительные рекомендации
- Для предобученных моделей (pretrained models): просто запустите готовый код, подставив свою модель, не изменяя фиксированные параметры.
- Для SFT-моделей: добавьте системный промпт в код и обязательно укажите его при сабмите, чтобы обеспечить воспроизводимость результатов.
Пример корректного форматирования сабмита доступен здесь.
Что нового в MERA v.1.2.0?
Первая версия бенчмарка MERA была представлена в ноябре 2023 года и описана в академической публикации.
С сентября 2024 года бенчмарк MERA обновился до версии 1.2.0, и теперь поддерживается только она. Вся информация на сайте и в GitHub-репозитории актуальна исключительно для этой версии, поэтому мы рекомендуем пользователям ориентироваться на нее. Подробнее о различиях между новой и предыдущей версиями можно прочитать в посте на Хабр.
Могу ли я протестировать свою проприетарную модель на MERA?
Да, можете! Мы подготовили код для оценки через фреймворк lm-harness, в том числе для API-моделей. Запустите тестирование своей модели и загрузите архив с результатами на сайт.
Скоры будут доступны вам в личном кабинете и останутся закрытыми для других пользователей.
Если вы хотите разместить свою модель на публичном лидерборде, при сабмите укажите как можно больше информации о ней:
- процесс обучения,
- использованные данные,
- архитектуру,
- параметры системы.
Эти сведения помогут сообществу понять и воспроизвести вашу систему. Сабмит проходит модерацию экспертами, которые могут связаться с вами для уточнения деталей.
Важно: даже если ваша модель будет опубликована в рейтинге, её ответы останутся доступными только экспертам и не будут раскрыты широкой публике.
Поддержка Chat Template и системных промптов: что это и зачем нужно?
- Chat Template — это алгоритм, который преобразует список сообщений в строку, передаваемую на вход модели. Сообщения записываются в формате JSON, например:
[{“role”: “system”, “content”: “брат, помоги решить задачу”}, {“role”: “user”, “content”: “сколько будет 2+2”}].
- Cистем промпт — это инструкция для модели, которая указывается в поле
{“role”: “system”, “content”: “СИСТЕМНЫЙ ПРОМПТ”}. Он задаёт контекст и поведение модели.
Эти два элемента важны, так как позволяют учитывать способ дообучения инструктивных моделей. Если разработчик использует Chat Template и системные промпты во время тестирования, оценки, как правило, оказываются более высокими.
Обратите внимание на Multi-turn режим в Hugging Face для моделей ассистентов. Он изменяет способ формирования промптов, включая few-shot примеры. Это может значительно повлиять на оценку модели — например, семейство моделей LLaMA без Multi-turn режима оценивается некорректно.
Лидерборд поддерживает все три параметра (chat template, системный промпт и multi-turn режим) и имеет отдельные фильтры для замеров, использующих такие настройки.
Можно ли замерять на MERA модели по API?
Да! Начиная с версии v.1.2.0 бенчмарк MERA поддерживает оценку моделей по API. Для этого необходимо только добавить в кодовую базу поддержку вашей модели. Инструкцию от авторов lm-evaluation-harness по добавлению API в фреймворк можно прочесть здесь.
Как добавить свой результат на публичный лидерборд?
По умолчанию загруженные сабмиты остаются приватными. Чтобы сделать результат публичным, отметьте опцию «Опубликовать». После этого администраторам MERA (они же члены экспертного совета бенчмарка) придет запрос на проверку. Если сабмит соответствует требованиям, его одобрят, и вы получите уведомление на email. Ваша модель появится на лидерборде. В случае необходимости с вами могут связаться для уточнения деталей.
Чтобы сабмит приняли к публикации, он должен содержать:
- Результаты по всем основным заданиям;
- Описание решения (как минимум ссылку на модель, статью или описание модели с деталями обучения);
- Полный перечень использованных ресурсов (источники данных, параметры моделей и другие ключевые детали).
Если вы обновите сабмит, процесс проверки повторится. Перед отправкой убедитесь, что все данные указаны корректно, а описание максимально подробное.
Есть ли ограничения на сабмиты и модели?
Вы можете использовать любые публичные или приватные данные при разработке и обучении языковых моделей, за исключением следующих случаев:
- Для тестирования необходимо использовать только данные с официального сайта или репозитория MERA, либо с официального Hugging Face. Данные из других источников могут содержать некорректное разбиение, ID или иной набор метаданных.
- Запрещено использовать неразмеченные тестовые данные MERA для обучения модели или как-либо передавать информацию между тестовыми примерами. Обучаться на тестовых данных — ненаучно и неэтично!
- Тренировочные и валидационные данные предоставляются участникам только в качестве примеров и для few-shot тестирования.
Вы можете отправлять результаты любой модели, при условии, что соблюдается формат, совпадают id вопросов и метки (labels). Мы оцениваем системы на основе машинного обучения, а не ручное решение задач!
Можно ли сделать анонимный сабмит на публичном лидерборде?
Можно. В лидерборде отображаются названия команд и моделей, но вы можете сделать анонимный аккаунт. Главное, чтобы участники и администраторы могли с вами связаться.
Под какой лицензией выложены датасеты?
Все задачи оригинального MERA собраны и обработаны на основе открытых источников. Все наборы данных публикуются по лицензии MIT.
Почему я не вижу результаты моей модели/сабмита?
Если вы отправили сабмит на оценку, для начала подождите — обработка модели может занять некоторое время.
Затем проверьте, что ваш сабмит загрузился в системe — он появится в списке ваших сабмитов. В противном случае появится сообщение об ошибке.
В остальных случаях, если сабмит почему-то не сработал — свяжитесь с нами по адресу mera@a-ai.ru
В случае некорректного сабмита система выдаст текстовое описание ошибки, которое покрывает случаи вида:
- В загруженном zip архиве нет какого-то из необходимых файлов для заданий.
- Что-то не так с метаданными (например, вы пропустили ID). Все ID для каждого из заданий в JSON обязательны и начинаются с 0. Проверьте, что все ID соответствуют тестовому сету.
Я нашел ошибку, у меня есть предложения и комментарии!
Вы можете связаться с нами по почте: mera@a-ai.ru. По предложениям и ошибкам в коде оценки или данных, пожалуйста, создавайте Issues в нашем официальном GitHub-репозитории.
Для оперативной связи работает telegram-чат техподдержки.
Сколько заданий в MERA?
- 15 тестовых задач с закрытыми ответами (задачи рейтинга). На основе этих задач рассчитывается рейтинг моделей на лидерборде.
- 8 диагностических задач с открытыми ответами. Эти задачи не учитываются в рейтинге моделей.
Какие диагностические задания есть в MERA?
Бенчмарк включает 8 диагностических датасетов с открытыми ответами:
- BPS — диагностический датасет для измерения способностей языковых моделей понимать алгоритмические концепции CS. Цель даного задания — определить сбалансирована ли скобочная последовательность или нет.
- ruHateSpeech — диагностический датасет на выявление способностей модели распознавать негативные высказывания, направленные на определенную группу людей.
- ruDetox — диагностический датасет по детоксификации. Задача — переписать токсичную реплика в корректном стиле.
- ruEthics — диагностический датасет для оценки восприятия понятия этики языковыми моделями.
- ruHHH — диагностический датасет на оценку честности/вреда/помощи, которые потенциально может нанести модель; аналог английского HHH.
- ruHumanEval — диагностический датасет на основе английского датасета HumanEval для оценки способности языковых моделей генерировать код на языке программирования Python для решения простых задач.
- ruMMLU — диагностический датасет на основе английского датасета MMLU, тестирующий профессиональных знаний модели, приобретенных в процессе предобучения в различных областях.
- SimpleAr — диагностический датасет на базовые арифметические возможности языковых моделей. В задании требуется выполнить сложение n-значных чисел (для n в диапазоне [1;5])
Эти датасеты не используются при общей оценке модели, а предназначены для выявления этических байесов модели, анализа ее безопасного применения и базовых алгоритмических навыков. Вы можете прогнать эти датасеты через кодовую базу проекта и получить сразу результаты, не отправляя на сайт сабмит.

 GitHub
GitHub