
Описание задачи
Russian Code Evaluation (ruCodeEval) — это созданный с нуля! российский аналог оригинального датасета HumanEval, созданного для оценки способности языковых моделей генерировать код на языке программирования Python для решения простых задач. Датасет направлен на измерение функциональной корректности генерируемого кода на основе информации из документации функции — текстового описания работы функции и нескольких примеров результатов для различных входных данных.
Ключевые слова: PLP, программирование, Python
Мотивация
Эта задача тестирует способность моделей генерировать простые программы на языке Python на основе описания (условия) на естественном языке. Так как в обучающем корпусе крупных моделей присутствует определённая доля текстов (программ), написанных на различных языках программирования, предполагается, что они могут понимать и писать код для простых задач.
Поля данных
instruction— строка, содержащая формулировку запроса к языковой модели;inputs— словарь, содержащий входные данные задания:function— строка, содержащая сигнатуру функции, а также ее док-строку в виде недописанной функции;tests— строка со списком словарей, которая содержит входные данные тестовых кейсов для данной задачи (вариантов входных данных, на которых тестируется итоговый код функции);
outputs— двумерный массив строк размера (n_samples, n_tests), где n_samples - количество сэмплов, требуемое для подсчета метрики pass@k, n_tests - количество тестовых кейсов в tests; каждый список в outputs одинаков и содержит корректные ответы в виде строк на все тестовые кейсы.meta— cловарь, содержащий метаинформацию:id— номер примера;canonical_solution— каноническое решение задачи [только в трейн сете];entry_point— имя функции.
Промпты
Для задачи было создано 10 промптов различной сложности. Пример:
"Допишите код на языке Python в соответствии с условием, приведенным в описании\n{function}"
Создание датасета
Датасет был собран вручную из открытых источников в соответствии с форматом оригинального датасета openai_humaneval, с корректировкой датасета для предотвращения утечки данных из оригинального датасета и учётом исправлений, описанных в [2].
Оценка
Метрики
Оценка модели осуществляется с помощью метрики pass@k, которая вычисляется следующим образом:
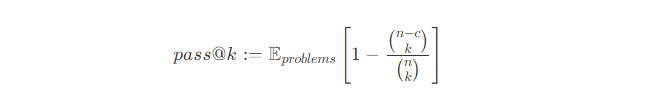
Обозначения: n — это общее количество сгенерированных вариантов решений, c — количество правильных решений, k — это выбранный индикатор, сколько вариантов учитывается.
Чтобы вычислить pass@k, для каждой задачи генерируется n ≥ k решений, которые прогоняются через тестовые данные (мы используем n = 10 и k ≤ 10, а в среднем для одной задачи есть 10 тестов). Затем подсчитывается количество правильных решений (c ≤ n). Решение считается правильным, если оно проходит все тесты. Это значит, что результат выполнения решения на тестах должен совпадать с правильными ответами (outputs) для одной задачи. Такой процесс оценки даёт объективный результат.
Человеческая оценка
Датасет включает алгоритмические задачи, требующие знания языка программирования Python, что является слишком сложным навыком для среднего аннотатора. Все задачи имеют строгие решения, поэтому все метрики оценки человеком принимаются как 1.0.
Ссылки
[1] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[2] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, Lingming Zhang Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation.