
Бенчмарк для современных текстовых русскоязычных моделей
| {{ task.title }} |
|---|
| {{ getTaskScore(submit, task) }} |
| {{ column.title }} |
|---|
| {{ getSubcategoryColumnValue(submit, column) }} |
Нет подходящих результатов
Новый стандарт в оценке современных моделей
Быстрее, точнее, удобнее — объективный анализ без лишних сложностей

Комплексный подход
MERA оценивает AI в разных сферах, тестируя способности моделей — от экспертных знаний до этики

Реальные сценарии
Наши тесты созданы с нуля, адаптированы под русский язык и культуру, чтобы результаты были максимально полезными

Открытость и прозрачность
MERA дает открытый код, фиксированные параметры запусков и детальные отчеты, помогая глубже понять модели
Партнеры и участники проекта
















Комплексная экспертиза для ваших решений
Подход сочетает количественные метрики и качественный анализ, позволяя выявить отклонения, ограниченность обобщения и потенциальные источники ошибок на разных этапах
Независимый лидерборд для оценки современных моделей
- Сравнение последних фронтиер-моделей ИИ
- Определение лучших моделей в конкретных областях и знаниях
- Полезный инструмент для разработчиков для анализа и выбора оптимальной модели под свои нужды
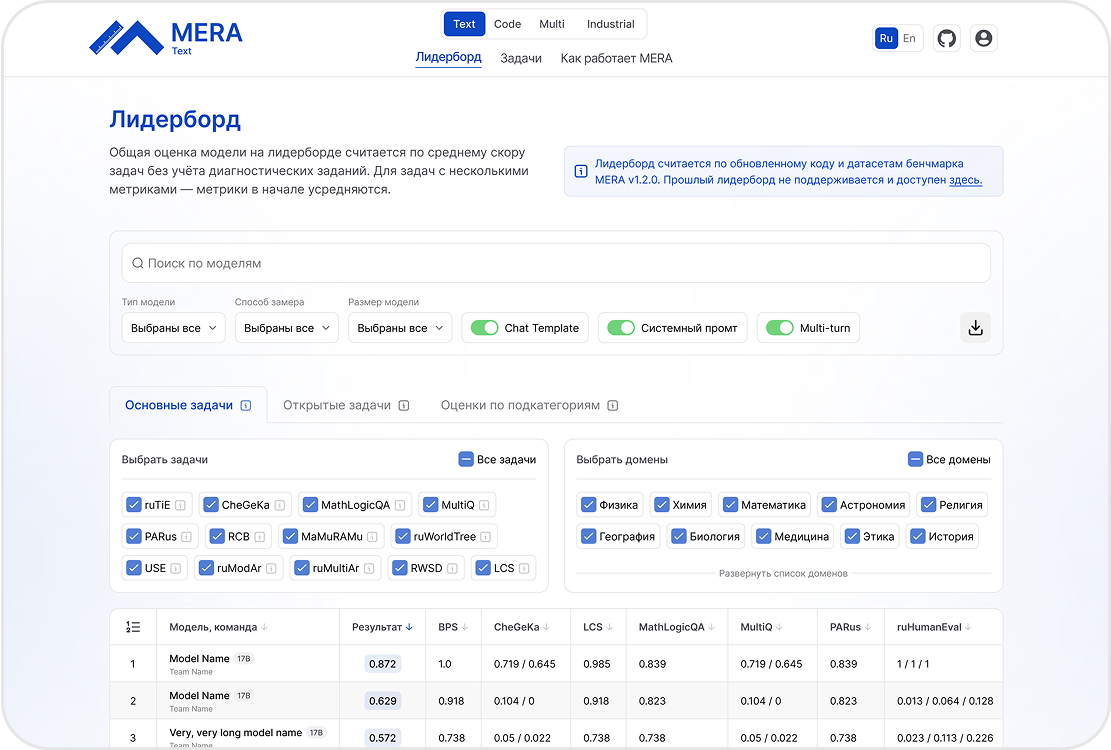
Задачи для любого уровня экспертизы
- Простые в использовании, но сложные для современных моделей тесты
- Продвинутые задачи для глубокой аналитики и оптимизации
- Каталог задач с детальной информацией о тесте и его создании
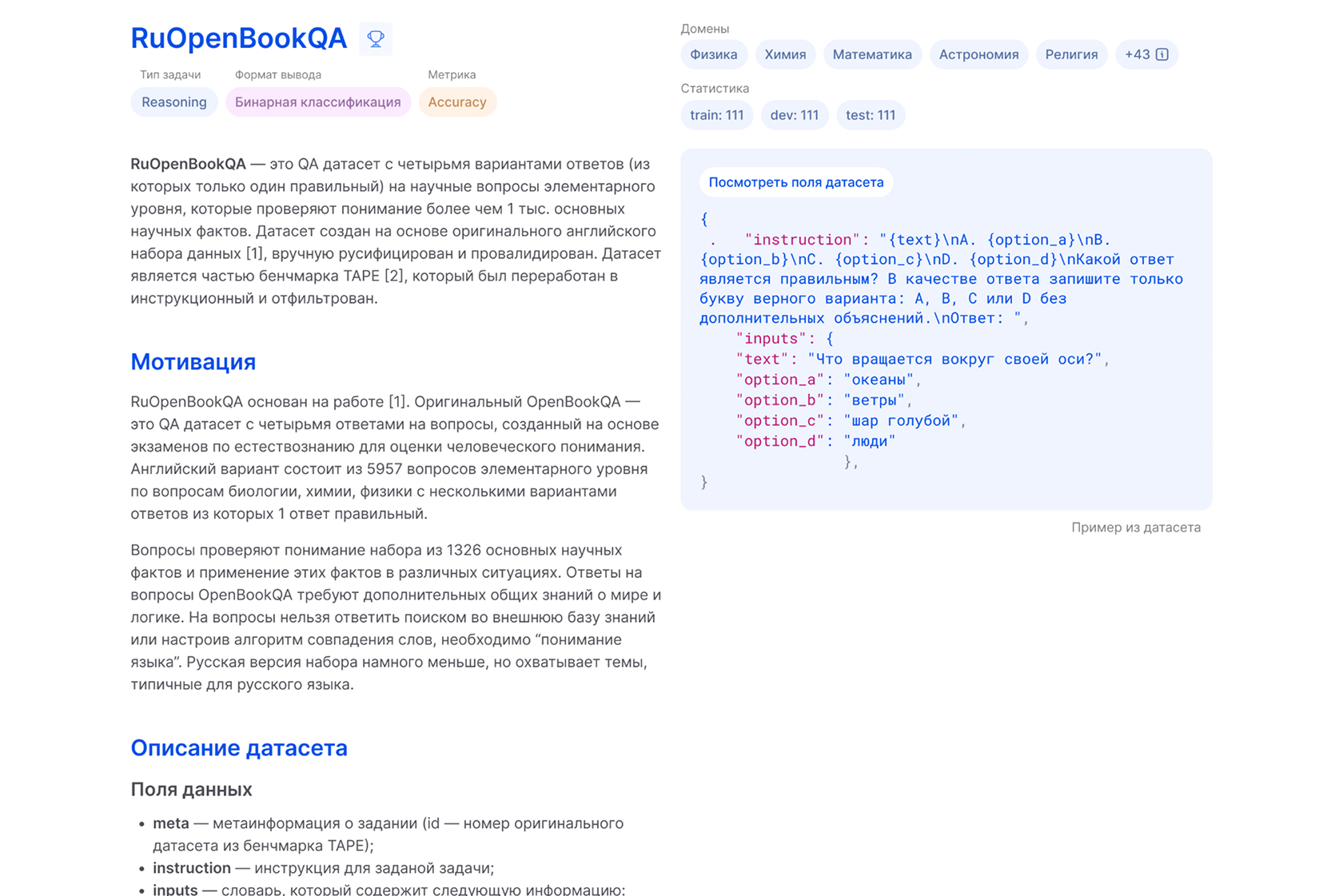
Управляйте сабмитами в личном кабинете
- Быстрая регистрация
- Все активные сабмиты под рукой
- Подробные результаты оценки по задачам
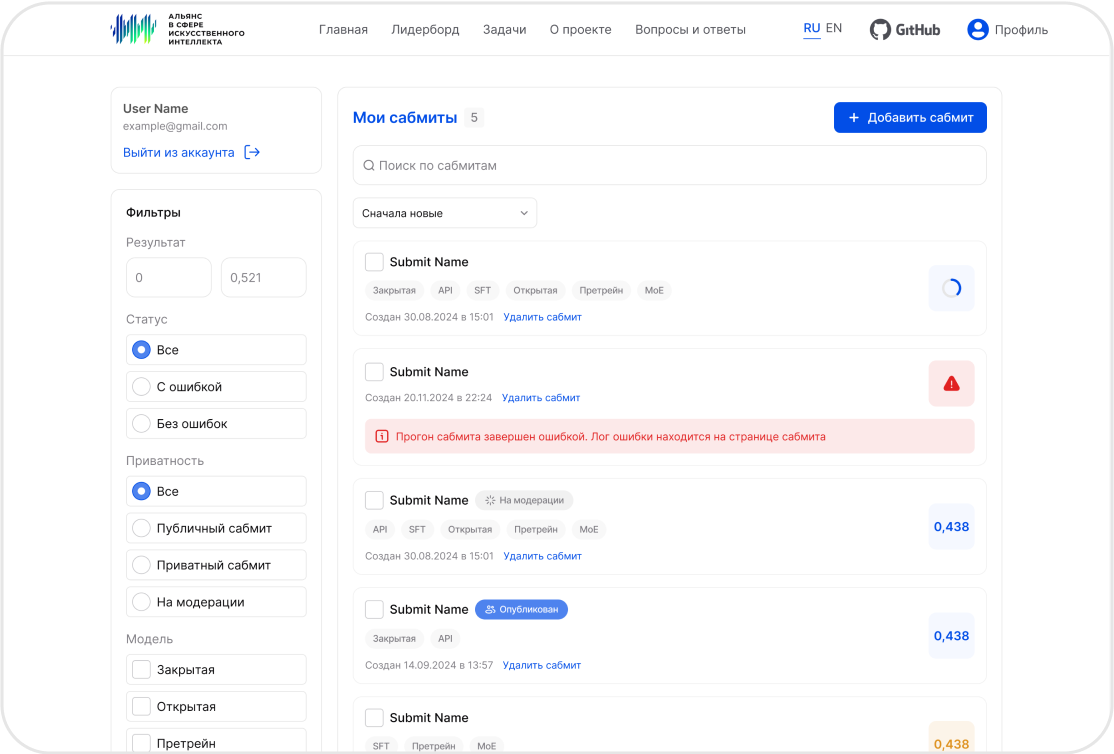
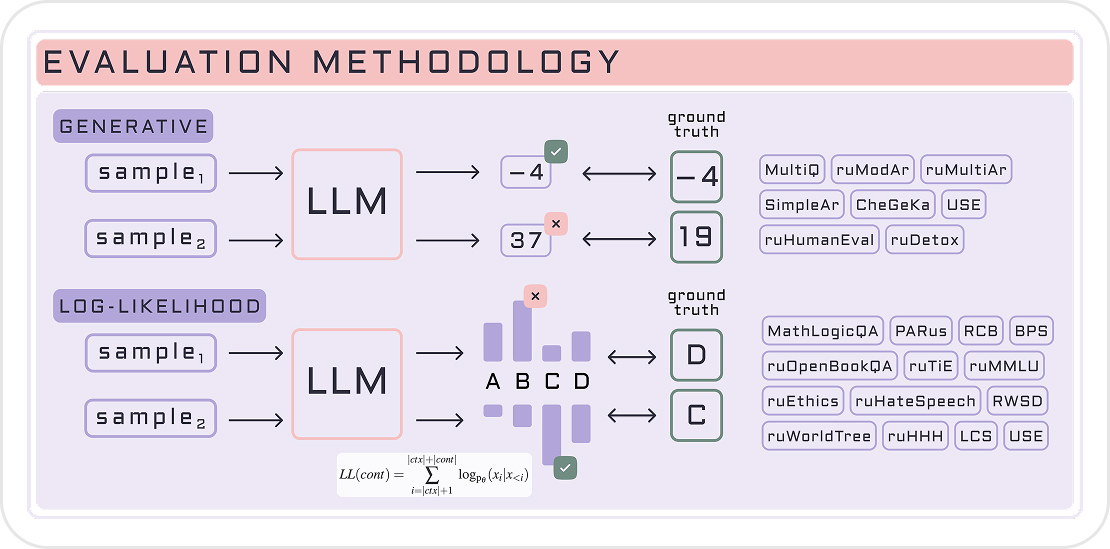
Прозрачная методология тестирования генеративных моделей
Ознакомьтесь с подробным описанием методологии создания бенчмарка
Оцените модели за минуты, а не недели
Отправляйте сабмиты, отслеживайте результаты и сравнивайте модели в одном месте


Объединяем лидеров для будущего технологий
Альянс в сфере искусственного интеллекта — это уникальная организация, созданная для объединения усилий ведущих технологических компаний, исследователей и экспертов. Наша миссия — ускоренное развитие и внедрение искусственного интеллекта в ключевые сферы: образование, науку и бизнес.
Узнать больше про Альянс
 GitHub
GitHub